LLMOps with DSPy: Build RAG Systems Using Declarative Programming : Puneet Mangla
by: Puneet Mangla
blow post content copied from PyImageSearch
click here to view original post
Table of Contents
LLMOps with DSPy: Build RAG Systems Using Declarative Programming
In this tutorial, we will explore DSPy — an open-source framework to perform LLMOps (Large Language Model Operations) in Python without prompt tuning.

Imagine a world where you can program your language models without the need to develop and tune prompts manually! To use Large Language Models (LLMs) for complex LLMOps tasks, you often need first to break down the problem into several sub-problems, do manual prompt tuning for each of these sub-problems, and combine all the steps so that everything works together. This becomes hard and messy every time your LLMOps pipeline needs to be changed.
Come to our rescue — DSPy (Declarative Self-Improving Language Python Programs). This open-source declarative programming framework takes a unique approach by prioritizing programming over prompt tuning during the development of LLMOps workflows. Unlike other frameworks that rely on fine-tuning models with prompts, DSPy empowers developers to write concise Python code that algorithmically performs prompt tuning for LLMOps workflows. By eliminating the need for trial-and-error prompts, DSPy streamlines the development process and enhances model performance.
In this tutorial, we’ll demystify the DSPy framework and guide you through the process of programming (not prompt tuning) a RAG system using DSPy. Let’s dive into the world of code-driven RAG systems with DSPy, the ultimate prompt generator for LLMOps! 🚀
To learn how to implement code-driven RAG systems in DSPy, just keep reading.
Introduction to DSPy: LLMOps Without Prompt Tuning
Imagine you’re building a complex LLMOps workflow. Traditionally, this involves manual steps like prompt tuning, tweaking parameters, and fine-tuning smaller models. It’s like writing code from scratch, adjusting every detail by hand.
Now, consider DSPy (Declarative Self-Improving Language Python Programs) as your toolkit. It is like PyTorch but for Language Models (LMs). DSPy streamlines the process of optimizing LM prompts and weights. Instead of manual adjustments, DSPy uses algorithms for prompt tuning and model fine-tuning.
Just as a Deep Learning framework like PyTorch or TensorFlow provides building blocks (e.g., Convolutions, Dropout, BatchNormalization, Dataloaders, etc.) for building neural networks, DSPy offers various declarative programming modules (e.g., ChainOfThought, ReAct, etc.) to replace string-based manual prompt tuning.
Just as how PyTorch or TensorFlow provides inbuilt optimizers (e.g., SGD, Adam, etc.) to learn the best parameters, DSPy gives you general optimizers (e.g., BootstrapFewShotWithRandomSearch or MIPRO) to update the parameters (prompt and LM weights) in an algorithmic fashion (analytical to backpropagation).
In short, DSPy (Figure 1) is to LMs as PyTorch or TensorFlow is to neural networks: a powerful toolset that automates and enhances the process, making it less about manual prompt tuning and more about systematic improvement and higher performance.
With DSPy, one can programmatically teach large language models (e.g., GPT-3.5 or GPT-4) or even local models (e.g., T5-base or Llama2-13b) to be much more reliable at solving downstream tasks (i.e., having higher quality and avoiding specific failure patterns).
Building Blocks of DSPy
Now, we will describe the building blocks (Figure 2) of DSPy:
Language Models
DSPy is a declarative programming framework that provides a simple syntax to load and use any language model in our program. To use a language model, we can call the constructor that connects to the language model and then use dspy.configure to set this as our default language model. For example, we can load and directly call the OpenAI language models as follows:
import dspy
import os
os.enviorn[“OPENAI_API_KEY”] = “YOUR OPENAI API KEY”
gpt3_turbo = dspy.OpenAI(model='gpt-3.5-turbo-1106', max_tokens=300)
dspy.configure(lm=gpt3_turbo)
gpt3_turbo("hello! this is a raw prompt to GPT-3.5")
In general, you can load language models hosted by remote services (e.g., OpenAI, Cohere, Anyscale, Together, PremAI, etc.) with the following format:
lm = dspy.{provider_listed_below}(model="your model", model_request_kwargs="...")
where {provider_listed_below} can be dspy.OpenAI, dspy.Cohere, dspy.Anyscale, dspy.Together, dspy.PremAI, etc.
We can also directly install the local language models from Hugging Face or Ollama using dspy.HFModel or dspy.OllamaLocal as follows:
mistral = dspy.HFModel(model = 'mistralai/Mistral-7B-Instruct-v0.2') ollama_mistral = dspy.OllamaLocal(model='mistral')
Signatures
DSPy signatures (Figure 3) are a way to specify the input-output behavior of a DSPy module. They are a way to tell your LMs what they should expect as input and what they should emit as output. It is analogous to how function signatures work in programming languages (e.g., C++, Java, Python, etc.) but with the following subtle differences:
- While function signatures can only describe things, DSPy Signatures describe as well as control the behavior of a module.
- The field names matter in DSPy Signature. You express semantic roles in plain English: a
questionis different from ananswer, and ansql_queryis different frompython_code.
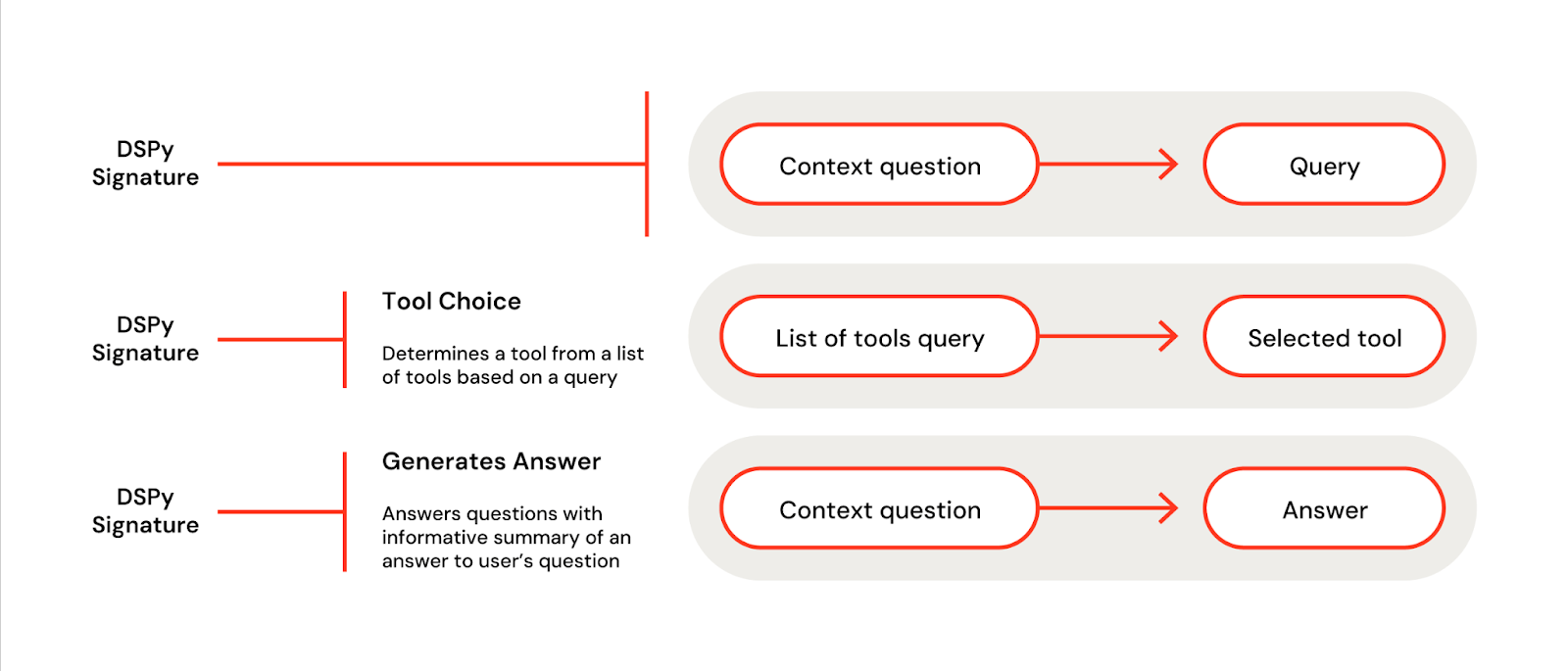
DSPy signature (Figure 4) can be described in a short string with input and output field names. Here are DSPy signatures for some standard tasks:
- Question answering:
“question -> answer” - Sentiment classification:
“sentence -> sentiment” - Summarization:
“document -> summary” - Multiple Choice Q/A with reasoning:
“question, choices -> reasoning, selection” - Retrieval Augmented Generation:
“question, context ->answer”

As long as the field names (in both input and output) are semantically similar, two DSPy signatures are expected to behave the same. For example, all of the following DSPy signatures should work for a text summarization task:
“document -> summary”“text -> gist”“long_text -> tldr”“document -> abstract”
The following snippet shows how we can use the DSPy signatures with LMs:
import dspy
import os
os.enviorn[“OPENAI_API_KEY”] = “YOUR OPENAI API KEY”
gpt3_turbo = dspy.OpenAI(model='gpt-3.5-turbo-1106', max_tokens=300)
dspy.configure(lm=gpt3_turbo)
# Define a module (ChainOfThought) and assign it a signature (return an answer, given a question).
qa = dspy.ChainOfThought('question -> answer')
# Run with the default LM configured with 'dspy.configure' above.
response = qa(question="How many floors are in the castle David Gregory inherited?")
print(response.answer)
One can also define a custom DSPy Signature for advanced tasks with the following three items:
- A
docstringto clarify and provide a high-level description of the task. - Use
dspy.InputField(desc=”description of field”)to define an input with its high-level description. - Use
dspy.OutputField(desc=”description of field”)to define an output with its high-level description.
Here’s how you can define a custom signature for a classification task:
class Emotion(dspy.Signature): """Classify emotion among sadness, joy, love, anger, fear, surprise.""" sentence = dspy.InputField() sentiment = dspy.OutputField() sentence = "i started feeling a little vulnerable when the giant spotlight started blinding me" # from dair-ai/emotion classify = dspy.Predict(Emotion) classify(sentence=sentence)
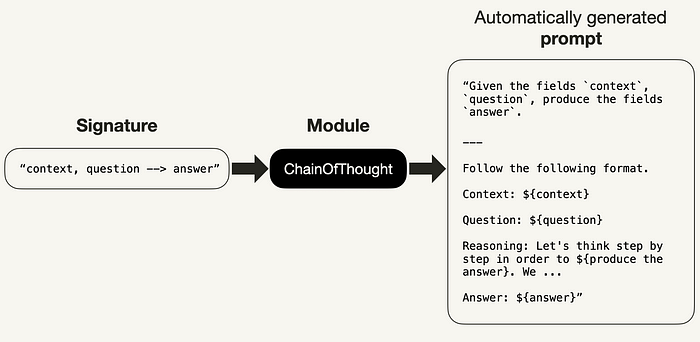
Modules
Similar to PyTorch’s nn.Module, DSPy modules (Figure 5) are the building blocks of an LM program. They consist of learnable parameters (prompt pieces, LM weights, etc.) and various prompt tuning techniques (like a forward pass function definition in PyTorch).
Here are some of the standard DSPy modules:
dspy.Predict: A basic predictor that doesn’t modify the signature. Ideal for simple tasks like sentiment classification.dspy.ChainOfThought: Teaches LM to think in a step-by-step fashion before reaching the answer. Internally, it modifies the original DSPy signature to incorporate a chain-of-thought reasoning. However, the final program adheres to the given DSPy signature.dspy.ProgramOfThought: Teaches LM to think in terms of executable programs, whose executable results guide the final answer. For a DSPy Signature"input_fields -> output_fields", Program-of-Thought (PoT) module internally creates the following intermediate signatures:- It first generates a Python code for the given inputs:
"input_fields -> generated_code" - The
generated_codeis then refined by looking at the previously generated code and its errors:"input_fields, previous_code, errors -> regenerated_code" - The output of the
regenerated_codeis then used to output the final answer:"input_fields, regenerated_code, code_ouptut -> output_fields"
- It first generates a Python code for the given inputs:
dspy.MultiChainComparison: This module can compare outputs from multipledspy.ChainOfThoughtmodules to produce the final output.
Several other modules can be checked out from the official documentation: DSPy modules.
Data
To represent examples in our training set, we use dspy.Example. Just like a Python dictionary, dspy.Example stores different attributes (question, answer, context, etc.) of an example. This is how we can define an example with inputs in DSPy:
qa_pair = dspy.Example(question="This is a question?", answer="This is an answer.")
print(qa_pair)
print(qa_pair.question)
print(qa_pair.answer)
# Single Input.
print(qa_pair.with_inputs("question"))
# Multiple Inputs; be careful about marking your labels as inputs unless you mean it.
print(qa_pair.with_inputs("question", "answer"))
Metrics
A metric in DSPy is a function that takes the output of the program and computes how similar, relevant, or accurate it is compared to an expected output. The metric function can be as simple as “accuracy”, “exact-match”, and “f1-score” for simple classifications and short Q/A (True-False, Yes-No, one-word formats) tasks.
For complex tasks (e.g., where output is long text format), the metric function can be another DSPy program that evaluates the output along multiple dimensions (possibly using another language model such as GPT-4).
Here’s an example of how you can define metrics in DSPy:
def validate_context_and_answer(example, pred, trace=None):
# check the gold label and the predicted answer are the same
answer_match = example.answer.lower() == pred.answer.lower()
# check the predicted answer comes from one of the retrieved contexts
context_match = any((pred.answer.lower() in c) for c in pred.context)
if trace is None: # if we're doing evaluation or optimization
return (answer_match + context_match) / 2.0
else: # if we're doing bootstrapping, i.e. self-generating good demonstrations of each step
return answer_match and context_match
The following are some built-in metrics in DSPy:
dspy.evaluate.metrics.answer_exact_matchdspy.evaluate.metrics.answer_passage_match
The metric above will return a float value if trace is None (i.e., if it’s used for evaluation or optimization) and will return a bool otherwise (i.e., if it’s used to bootstrap demonstrations).
Optimizers
A DSPy optimizer (Figure 6) is an algorithm that tunes the parameters of the program (e.g., prompt or LM weights) in order to maximize a given metric on a training set, just as how PyTorch optimizers work in order to minimize a loss function.
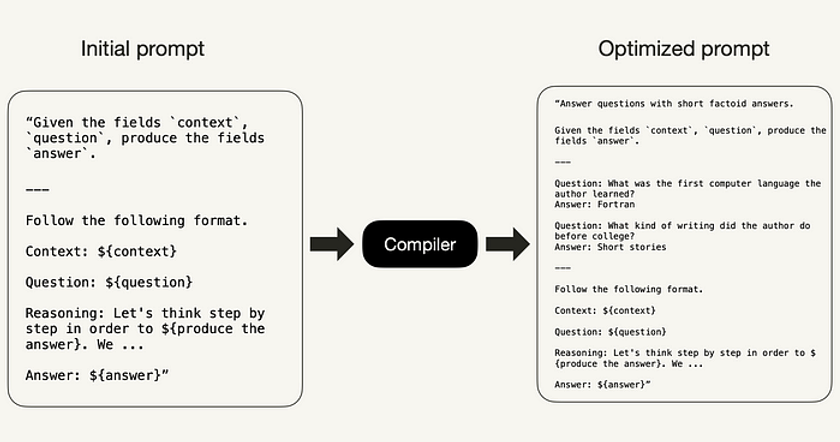
A typical DSPy optimizer takes 1) a DSPy program or module, 2) a metric function, and 3) a few training examples to work.
Optimizing a DSPy program involves several calls to LMs, inspecting data, simulating traces through the program, and generating good/bad examples (based on a given metric) for each step. The DSPy optimizer then proposes or refines instructions based on these examples, surpassing human prompt creation capabilities.
It can also adjust LM weights (via gradient descent) on self-generated examples to improve quality or reduce costs. Automation streamlines prompt tuning and fine-tuning, enhancing language model programming efficiency.
Additionally, DSPy optimizes for demonstrations which are like few-shot examples to guide the input-output behavior of the program. These demonstrations can be generated from scratch to guide the behavior and working of programs in the best way.
The following are some of the built-in optimizers in DSPy:
LabelFewShot: Constructs few-shot examples by randomly selectingkexamples from the provided training set.BootStrapFewShot: Uses ateacherprogram (defaults to itself) to generate examples from scratch. At each step, it selectsmax_labelled_demossamples from the training set andmax_bootstrapped_demossamples generated by theteacherprogram.
Then, it employs the metric function to validate these examples and select the best demonstrations. This optimizer is ideal when you have very few examples in the training set (< 50).BootStrapFewShotWithRandomSearch: AppliedBootStrapFewShotseveral times along with random search on generated demonstrations, and selects the best program. This optimizer is ideal when you have a few examples in the training set ( 50-300).
50-300).MIPRO: This optimizer also produces the optimal instructions for the prompt along with the demonstrations. It employs advanced optimization techniques (e.g., Bayesian optimization) to generate instructions that are data-aware and demonstration-aware. This optimizer is ideal when you have large examples in the training set (> 300).
Here’s how we can use DSPy optimizers in our code:
from dspy.teleprompt import BootstrapFewShotWithRandomSearch # Set up the optimizer: we want to "bootstrap" (i.e., self-generate) 8-shot examples of your program's steps. # The optimizer will repeat this 10 times (plus some initial attempts) before selecting its best attempt on the devset. config = dict(max_bootstrapped_demos=4, max_labeled_demos=4, num_candidate_programs=10, num_threads=4) teleprompter = BootstrapFewShotWithRandomSearch(metric=YOUR_METRIC_HERE, **config) optimized_program = teleprompter.compile(YOUR_PROGRAM_HERE, trainset=YOUR_TRAINSET_HERE)
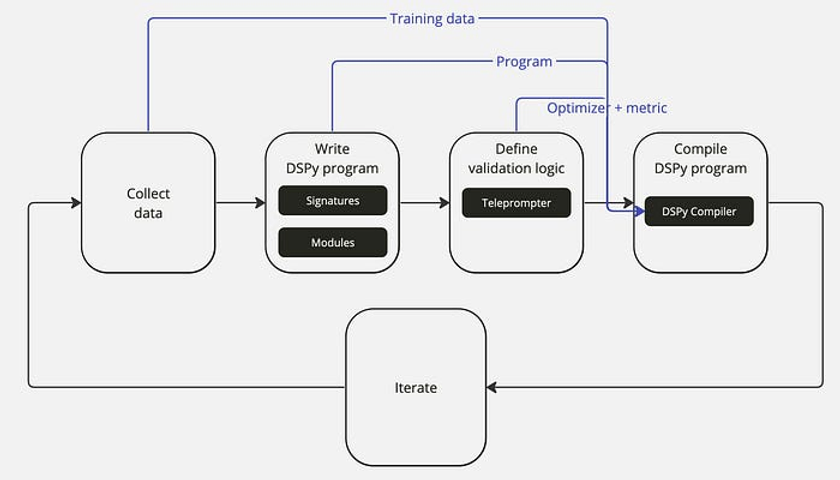
Figure 7 summarizes the LLMOps workflow with DSPy.
Building a RAG Framework for Biomedical Question Answering with DSPy
In this section, we will see how we can use the building blocks (explained in the previous section) to build a DSPy program that leverages Retrieval Augmented Generation (RAG) for Biomedical Semantic question answering (QA). Biomedical Semantic QA involves answering biomedical questions by retrieving relevant concepts, articles, and snippets from designated resources.
Overview and Setup
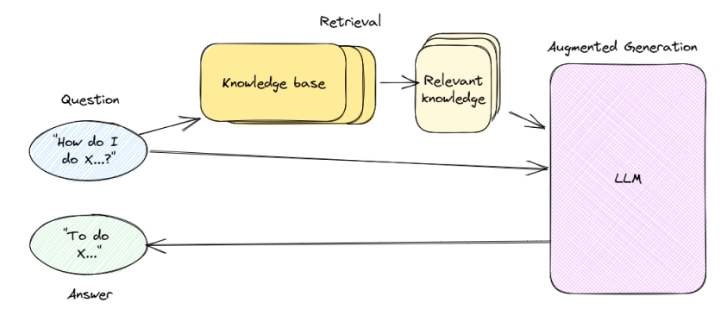
Retrieval Augmented Generation (RAG) is an advanced approach in natural language processing (NLP) that combines the strengths of retrieval-based and generation-based models to enhance the performance and accuracy of AI systems, particularly in tasks like question answering and conversational AI.
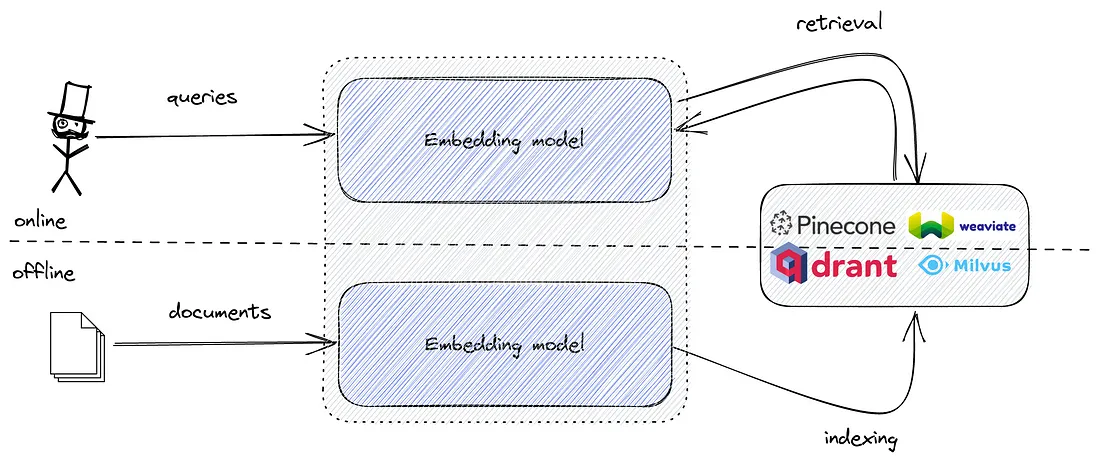
In the RAG system (Figure 8), the personalized data is organized in the form of an “index” for quick and precise retrieval. Whenever a user issues a query, the system searches to find the most relevant information related to the query from the index. The retrieved information, along with the original query and prompt, are then fed into the LLM for it to respond.
We will start by installing the DSPy package as follows:
pip install dspy-ai
Loading and Splitting the Dataset
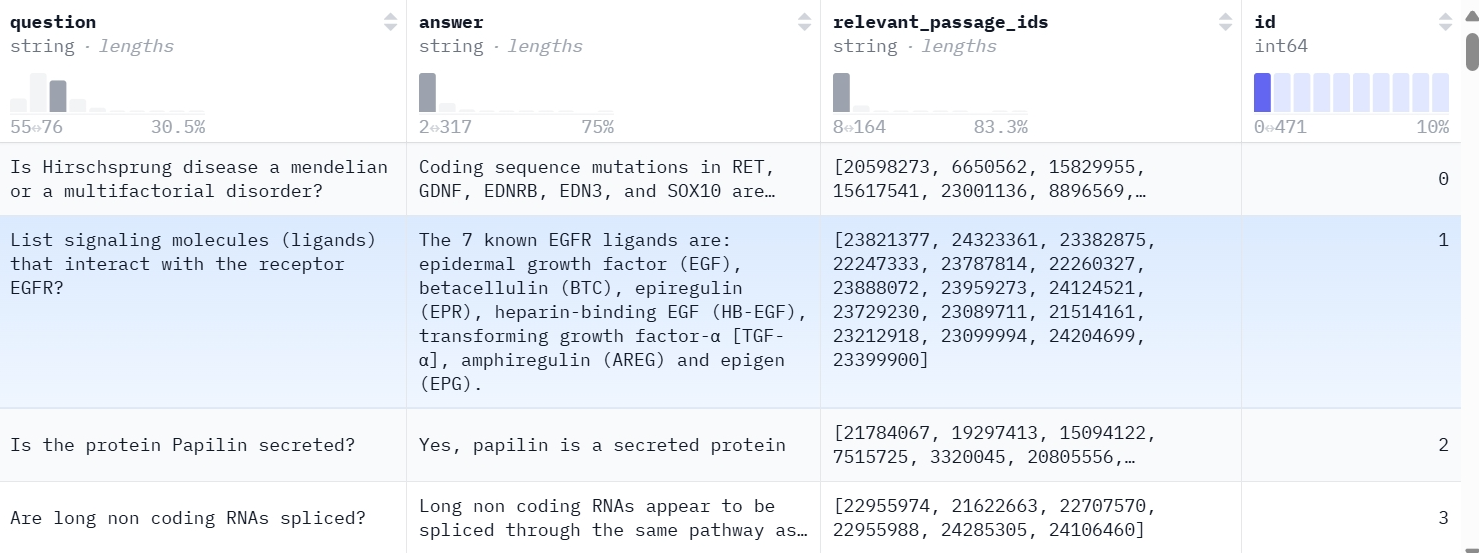
For this project, we will use the BioASQ mini dataset (Figure 9) that contains 40K document snippets (fetched from various designated resources) and 4.7K question-answer pairs for testing.
We will now load the BioASQ mini dataset and split it into train and validation sets.
import dspy
import pandas as pd
import random
passages = pd.read_parquet("hf://datasets/rag-datasets/rag-mini-bioasq/data/passages.parquet/part.0.parquet")
test = pd.read_parquet("hf://datasets/rag-datasets/rag-mini-bioasq/data/test.parquet/part.0.parquet")
dataset = []
# Compose DSPy examples
for index, row in test.iterrows():
dataset.append(dspy.Example(question=row.question, answer=row.answer).with_inputs("context", "question"))
random.shuffle(dataset) # Shuffle the dataset
# 50 examples for trainset and 10 examples for validation set
trainset, devset = dataset[:50], dataset[100:110]
print(len(trainset), len(devset))
Let’s break down the code step by step.
First, we import the necessary libraries: dspy, pandas, and random (Lines 1-3). We then load two datasets from parquet files using the pandas read_parquet function: passages and test (Lines 5 and 6). These datasets are likely part of a larger dataset used for training and testing a model, specifically from the RAG (Retrieval Augmented Generation) mini BioASQ dataset.
Next, we initialize an empty list called dataset (Line 8). We then iterate over each row in the test dataset (Line 11). For each row, we create a dspy.Example object with the question and answer from the row, and specify that the inputs are "context" and "question" (Line 12). These examples are appended to the dataset list. After creating all examples, we shuffle the dataset using random.shuffle to ensure randomness (Line 14).
Finally, we split the shuffled dataset into two subsets: trainset and devset (Line 17). The trainset consists of the first 50 examples, while the devset consists of 10 examples starting from the 100th position. We then print the lengths of these subsets to verify the split (Line 19).
Building the Retrieval Model
Next, we will build a retrieval model that can fetch relevant snippets from the text corpus. These relevant snippets will serve as a context for the language model to answer the given question. This is helpful for cases where the language model is not familiar with the concept or terminologies asked in the question.
In our retrieval model (Figure 10), we will use deep learning models such as all-MiniLM-L6-v2 to embed the document snippets and queries (questions in our case) into fixed dimensional embeddings. Once we have them, we can compute the cosine similarity between the document and query embeddings to fetch the topK documents relevant to the question.
In our case, we will use all-MiniLM-L6-v2, which is an embedding model that maps sentences and paragraphs to a 384-dimensional dense vector space and can be used for tasks like clustering or retrieval.
The model is fine-tuned on a 1 Billion sentence pairs dataset using a contrastive learning objective. Given a sentence from the pair, the model is trained to predict which, out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
To load all-MiniLM-L6-v2, we will first need to install the sentence-transformers library.
SentenceTransformers (a.k.a. SBERT) is the go-to Python module for accessing, using, and training more than 5000 state-of-the-art text and image embedding models.
Here’s how to install it using pip.
$ pip install sentence-transformers
We will leverage dspy.Retrieve module to implement a RetrievalModel class in order to fetch relevant snippets from the text corpus.
import numpy as np
from sentence_transformers import SentenceTransformer
class RetrievalModel(dspy.Retrieve):
def __init__(self, passages):
self.passages = passages
self.passages["valid"] = self.passages.passage.apply(lambda x: len(x.split(' ')) > 20)
self.passages = self.passages[self.passages.valid]
self.passages = self.passages.reset_index()
print(self.passages)
# 1. Load a pretrained Sentence Transformer model
self.model = SentenceTransformer("all-MiniLM-L6-v2", device="cuda")
self.passage_embeddings = self.model.encode(self.passages.passage.tolist())
def __call__(self, query, k):
query_embedding = self.model.encode(query)
similarities = self.model.similarity(query_embedding, self.passage_embeddings).numpy() # cosine similarities
top_indices = similarities[0, :].argsort()[::-1][:k] # pick TopK documents having highest cosine similarity
response = self.passages.loc[list(top_indices)]
response = response.passage.tolist()
return [dspy.Prediction(long_text= psg) for psg in response]
rm_model = RetrievalModel(passages=passages)
rm_model("Where is the protein Pannexin1 located?", 2)
Let’s walk through the code step by step.
First, we import the necessary libraries: numpy and SentenceTransformer from the sentence_transformers package (Lines 20 and 21). We then define a class RetrievalModel that inherits from dspy.Retrieve (Line 23). In the __init__ method, we initialize the class with a passages DataFrame. We filter the passages to include only those with more than 20 words and reset the index (Line 25-29). Next, we load a pretrained SentenceTransformer model (all-MiniLM-L6-v2) and encode the passages into embeddings (Lines 32 and 33).
In the __call__ method, we handle the retrieval process. We encode the query into an embedding and compute the cosine similarities between the query embedding and the passage embeddings (Lines 36 and 37). We then sort these similarities in descending order and select the top k indices (Line 38). Using these indices, we retrieve the corresponding passages from the DataFrame (Lines 40 and 41). Finally, we return a list of dspy.Prediction objects, each containing one of the top passages (Line 43).
To test the RetrievalModel, we create an instance of the class with the passages DataFrame (Line 45). We then call the model with a query (“Where is the protein Pannexin1 located?”) and specify that we want the top 2 results (Line 46). The model returns the most relevant passages based on the cosine similarity between the query and the passage embeddings.
Defining a DSPy RAG Module
Now, we will implement a DSPy program that mimics the RAG setup (i.e., the program takes a question and its context as inputs and outputs an answer).
We will define a DSPy module RAG() that will first fetch relevant context for the question (using our RetrievalModel class) and then use a chain-of-thought prompt tuning technique (via dspy.ChainOfThought) to enable step-by-step reasoning behavior.
We use the standard DSPy signature: "question, context -> answer" to enable Retrieval Augmented Generation.
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought("question, context -> answer")
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
In this code, we define a class RAG that inherits from dspy.Module (Line 47). We then set up two components: self.retrieve, which is an instance of dspy.Retrieve configured to retrieve num_passages passages and self.generate_answer, which is a dspy.ChainOfThought model designed to generate an answer from a given question and context (Lines 51 and 52).
In the forward method, we retrieve the context passages for the given question, generate a prediction using the retrieved context and the question, and return a dspy.Prediction object containing both the context and the generated answer (Lines 55-57).
Implementing the Metric Function
Next, we need a metric function that can score how similar the generated answer and the expected answer are. Since, in our case, answers can be long text, we will use another language model (e.g., OpenAI gpt-4-turbo-preview) to assess the similarity between the generated and expected answers.
To achieve this, we can create another DSPy program to prompt the language model to output a score between 1 to 5 (5 representing the highest similarity score).
# Define the signature for automatic assessments.
class Assess(dspy.Signature):
"""Check whether the generated answer and the given answer are similar"""
generated_answer = dspy.InputField(format=str)
given_answer = dspy.InputField(format=str)
assessment_score = dspy.OutputField(desc="1 to 5")
gpt4T = dspy.OpenAI(model='gpt-4-turbo-preview', max_tokens=1000, model_type='chat')
def metric(correct, pred, trace=None):
with dspy.context(lm=gpt4T):
answer = dspy.Predict(Assess)(generated_answer=pred, given_answer=correct)
score = int(answer.assessment_score.lower())
if trace is not None: return (score >= 4 and score <=5)
return score/5.0
pred = "Hello, this is David. He lives in South California"
correct = "David lives in South California"
print(metric(correct, pred))
Let’s break down the code step by step.
First, we define a custom DSPy signature Assess to check the similarity between a generated answer and a given answer. It includes two input fields, generated_answer and given_answer, both formatted as strings, and an output field assessment_score, which ranges from 1 to 5 (Lines 59-64). We also add a docstring at the start to clarify and provide a high-level description of the task.
Next, we initialize a language model gpt4T using dspy.OpenAI with the model set to 'gpt-4-turbo-preview' (Line 66).
The metric function takes three parameters: correct, pred, and an optional trace. Within this function, we use the dspy.context to set the language model to gpt4T and create an Assess object to compare the generated_answer (pred) with the given_answer (correct) (Lines 69-74). The score is normalized in the 0-1 range.
To test the metric function, we define two example strings, pred and correct (Lines 77 and 78), and print the result of the metric function when comparing these two strings. This setup allows us to automatically assess the similarity between generated and given answers using a language model.
Optimizing the DSPy Program
We will optimize our DSPy RAG program to maximize the custom metric function on the training split.
from dspy.teleprompt import BootstrapFewShot turbo = dspy.OpenAI(model='gpt-3.5-turbo') dspy.settings.configure(lm=turbo, rm=rm_model) # Set up a basic teleprompter, which will compile our RAG program. config = dict(max_bootstrapped_demos=4, max_labeled_demos=4) teleprompter = BootstrapFewShot(metric=metric, **config) # Compile! compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
In this code, we first import BootstrapFewShot from dspy.teleprompt and set up OpenAI gpt-3.5-turbo-instruct as our default language model. We also set up an instance of the RetrievalModel class as our default retrieval model (Lines 81-84).
We then create a DSPy BootstrapFewShot optimizer with a configuration that includes max_labeled_demos and max_bootstrapped_demos as 4 (Lines 87 and 88).
Finally, we compile the RAG program using the DSPy optimizer on the trainset (Line 91), resulting in a compiled RAG model ready for use.
Evaluating the DSPy Program
Now it’s time to test and evaluate our compiled RAG program. First, we will test it on a sample query.
# Ask any question you like to this simple RAG program.
my_question = "Where is the protein Pannexin1 located?"
# Get the prediction. This contains 'pred.context' and 'pred.answer'.
pred = compiled_rag(my_question)
# Print the contexts and the answer.
print(f"Question: {my_question}")
print(f"Predicted Answer: {pred.answer}")
print(f"Retrieved Contexts (truncated): {[c[:200] + '...' for c in pred.context]}")
Output:
Question: Where is the protein Pannexin1 located? Predicted Answer: The protein Pannexin1 (Panx1) is located at the plasma membrane and different subcellular compartments in astrocytes and neurons. Retrieved Contexts (truncated): ['Pannexin2 (Panx2) is the largest of three members of the pannexin proteins. \nPannexins are topologically related to connexins and innexins, but serve \ndifferent functional roles than forming gap junct...', 'Pannexins are a family of integral membrane proteins with distinct \npost-translational modifications, sub-cellular localization and tissue \ndistribution. Panx1 is the most studied and best-characteriz...', 'Pannexins (Panx) are proteins homologous to the invertebrate gap junction \nproteins called innexins (Inx) and are traditionally described as transmembrane \nchannels connecting the intracellular and ex...']
As we can see, the optimized RAG program correctly answers the question and also provides the retrieved contexts used for answering the questions.
from dspy.evaluate.evaluate import Evaluate # Set up the 'evaluate_on_hotpotqa' function. We'll use this many times below. evaluate_on_devset = Evaluate(devset=devset, num_threads=1, display_progress=True, display_table=10) evaluate_on_devset(compiled_rag, metric=metric)
We can also evaluate our optimized program on the validation set using dspy.evaluate.
Figure 11 displays the output of the above code.
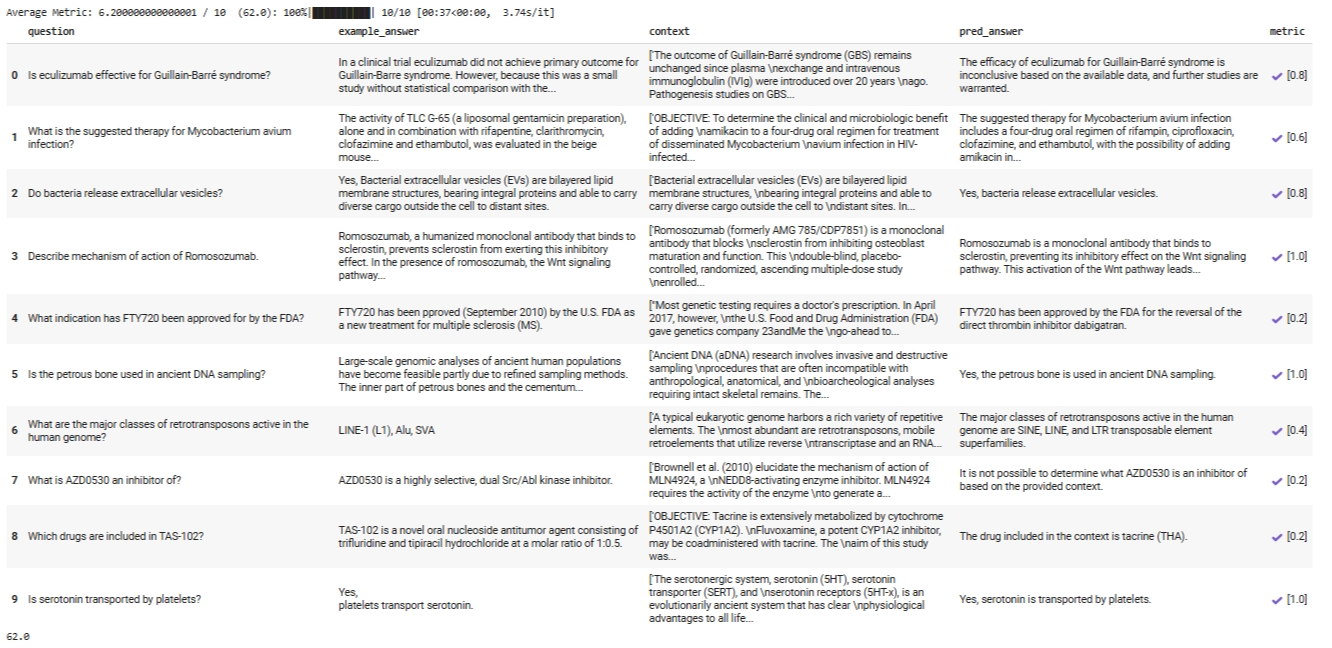
As you can see, the compiled RAG program achieves an average score of 0.62 (recall that the scores are normalized between 0 to 1) on the validation set, indicating a good performance.
What's next? We recommend PyImageSearch University.
84 total classes • 114+ hours of on-demand code walkthrough videos • Last updated: February 2024
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, “LLMOps with DSPy: Build RAG Systems Using Declarative Programming,” we delve into the innovative world of DSPy, a tool that allows us to manage LLMOps without the need for prompt tuning. We begin by introducing DSPy and its core components (e.g., language models, signatures, modules, data, metrics, and optimizers). These building blocks form the foundation of DSPy, enabling us to create robust and efficient systems for various applications.
We then shift our focus to constructing a Retrieval Augmented Generation (RAG) framework specifically designed for biomedical question answering (QA). Starting with an overview and setup, we guide you through the process of loading and splitting the dataset, building the retrieval model, and defining a DSPy RAG module. Each step is meticulously detailed to ensure that you can follow along and implement the framework effectively. We also cover the implementation of the metric function, which is crucial for evaluating the performance of our RAG system.
Finally, we discuss the optimization and evaluation of the DSPy program. By optimizing the DSPy program, we can enhance its performance and ensure it meets the desired metrics. We conclude by evaluating the program to validate its effectiveness in answering biomedical questions accurately. This comprehensive guide aims to equip you with the knowledge and tools needed to leverage DSPy for building advanced RAG systems, making complex tasks more manageable and efficient.
Citation Information
Mangla, P. “LLMOps with DSPy: Build RAG Systems Using Declarative Programming,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/a2qom
@incollection{Mangla_2024_LLMOps-DSPy-Build-RAG,
author = {Puneet Mangla},
title = {LLMOps with DSPy: Build RAG Systems Using Declarative Programming},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/a2qom},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.
The post LLMOps with DSPy: Build RAG Systems Using Declarative Programming appeared first on PyImageSearch.
September 09, 2024 at 06:30PM
Click here for more details...
=============================
The original post is available in PyImageSearch by Puneet Mangla
this post has been published as it is through automation. Automation script brings all the top bloggers post under a single umbrella.
The purpose of this blog, Follow the top Salesforce bloggers and collect all blogs in a single place through automation.
============================


Post a Comment