Spotify Music Recommendation Systems : Puneet Mangla
by: Puneet Mangla
blow post content copied from PyImageSearch
click here to view original post
Table of Contents
Spotify Music Recommendation Systems
In this tutorial, you will learn about Spotify’s music recommendation systems.

The Internet has revolutionized how we discover, consume, and interact with music. Free from the hassle of DVDs, cassettes, and audiotapes, we can now listen to music anytime and anywhere through streaming platforms (e.g., Spotify, Amazon Music, Apple Music, etc.).
With over 200M users worldwide, Spotify has become the industry leader in audio streaming services. They have extended from music to podcasts and audiobooks attracting users with diverse preferences and interests.
Behind the scenes are Spotify’s state-of-the-art music recommendation engines (Figure 1) that suggest music or podcasts to users based on their interests, preferences, and current mood. The recommendation systems have played a major role in providing a good user experience, which has resulted in such success for Spotify.

This lesson will cover several aspects of Spotify recommendations (e.g., music recommendation, playlist recommendation) and how they work behind the scenes.
This lesson is last of a 3-part series on Deep Dive into Popular Recommendation Engines 102:
- Amazon Product Recommendation Systems
- YouTube Video Recommendation Systems
- Spotify Music Recommendation Systems (today’s tutorial)
To learn how Spotify recommendation engines work, just keep reading.
Spotify Music Recommendation Systems
Even though the task of music recommendations might feel similar to movie recommendations (as we learned in Netflix recommendation systems), there are several differences in how both works:
- The song catalog is quite large compared to movies (Figure 2). The same song can have multiple variations (e.g., lo-fi, remix, slow, reverbed, different singer, band, etc.). However, movies are unlikely to have variations.

- Songs have a repetitive consumption pattern as you will likely listen to songs you like more often. However, it’s not the case with movies.
- Music is more niche compared to movies. Some might like folk songs, 1990s songs, pop or rock, or a certain band or singer.
- Ratings are more explicit in movies. However, for songs the feedback is hidden in the streaming pattern of the user.
Spotify has data about millions of songs, user tastes, streamed music, and user-generated playlists. We will now examine how Spotify uses these data sources and advance machine learning techniques to address the music recommendation problem.
Discover Weekly via Matrix Factorization
How Discover Weekly Works?
Spotify’s Discover Weekly (Figure 3) is an algorithm-generated playlist released every Monday to offer its listeners custom, curated music recommendations. Behind the scenes, Discover Weekly uses collaborative filtering to leverage user listening history and songs liked by users having similar histories. Recall that collaborative filtering recommends items to a user based on those liked by other users with similar interests.
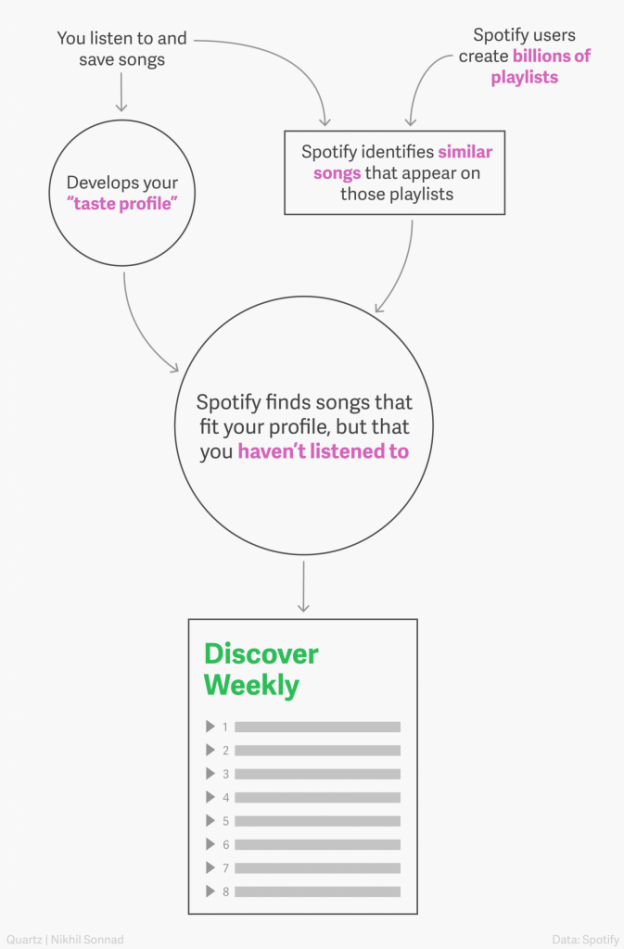
Spotify also establishes a taste profile by grouping the music users often listen into clusters. These clusters are not based on explicit attributes (e.g., genre, artist, etc.) but rather on the compositional similarity of songs.
Apart from explicit feedback such as library saves and “Liked from Radio,” Spotify relies on implicit feedback (e.g., song repeats, skipping songs, song clicks, etc.) to train their algorithm. It uses a matrix factorization-based approach that decomposes the user-item rating matrix into two segments. The first segment describes the users in terms of latent factors, each weighted differently. The second segment describes the songs, artists in the same latent space as the user segment.
Matrix Factorization
To understand clearly, let’s assume we have:
- A group of
 users,
users, ")
- A group of
 song items,
song items, ")
- User-item observation matrix
_{n \times m})") where
where  denotes the number of times user
denotes the number of times user  interacted with item
interacted with item  .
.
The design of the user-item observation matrix depends on the nature of the problem. One can choose to weigh the explicit feedback more compared to the implicit feedback. Additionally, one may choose to weigh more recent user streams higher than older streams as a user’s taste may change slightly over time.
Note that the matrix  is usually sparse since most users have only interacted with a limited number of items in the catalog. For user-items combinations where the user has not interacted with the item ,
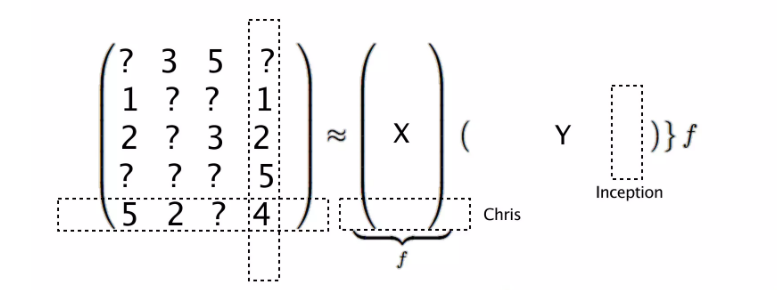
is usually sparse since most users have only interacted with a limited number of items in the catalog. For user-items combinations where the user has not interacted with the item ,  is set to zero. Matrix factorization (Figure 4) aims to approximate these values for unknown user-item combinations.
is set to zero. Matrix factorization (Figure 4) aims to approximate these values for unknown user-item combinations.

The approach (Figure 5) decomposes the observation matrix into two matrices:
- User Matrix:
![X_{N \times f} = [x_1, x_2, \dots, x_N]](https://b2633864.smushcdn.com/2633864/wp-content/latex/cf0/cf037a3fa2a9582367a0f1d256a6a853-ffffff-000000-0.png?lossy=2&strip=1&webp=1 "X_{N \times f} = [x_1, x_2, \dots, x_N]") describing each of the users via
describing each of the users via  latent factors
latent factors - Item Matrix:
![Y_{M \times f} = [y_1, y_2, \dots, y_M]](https://b2633864.smushcdn.com/2633864/wp-content/latex/ef9/ef9db81b1b98d5ff9985d7e82a471f50-ffffff-000000-0.png?lossy=2&strip=1&webp=1 "Y_{M \times f} = [y_1, y_2, \dots, y_M]") describing each of the songs via the same latent factors.
describing each of the songs via the same latent factors.
In other words,
 or
or

where  denotes the vector inner product operation.
denotes the vector inner product operation.
To learn matrices  and
and  , Spotify minimizes the following RMSE (Root Mean Square Error) loss between observation values
, Spotify minimizes the following RMSE (Root Mean Square Error) loss between observation values  and predicted values
and predicted values  .
.
^2 - \lambda \left(\sum_u \lVert x_u\rVert^2 + \sum_i \lVert y_i \rVert^2 \right)")
where  is a hyperparameter to control regularization:
is a hyperparameter to control regularization:  and
and  are biases of item and user .
are biases of item and user .
Alternating Least Squares
The matrices and are optimized using alternate least squares algorithm as follows:
Step 1: Initialize and randomly.
Step 2: Fix the item vectors  and solve for user vectors
and solve for user vectors  . Take the derivative of the above loss function with respect to user vectors and set it to zero, which gives
. Take the derivative of the above loss function with respect to user vectors and set it to zero, which gives
^{-1} Y^T R(u),")
where  is a constant multiplier and
is a constant multiplier and ") is the
is the  row of observation matrix .
row of observation matrix .
Step 3: Fix the user vectors and solve for item vectors (using the same procedure as Step 2). Take the derivative of the above loss function with respect to item vectors and set it to zero, which gives
^{-1} X^T R(i),")
where  is a constant multiplier and
is a constant multiplier and ") is the
is the  column of observation matrix .
column of observation matrix .
Step 4: Repeat until convergence.
RNNs for Music Discovery
In music consumption, the user behavior keeps changing from time to time and can be described by a trajectory in time along different artists and genres. For example, think of a user listening to an artist’s album for some time and then transitioning to the next album or a compilation playlist of the same musical genre. Using recurrent neural networks (RNNs) to leverage the user’s listening patterns, Spotify represents its users as a function of their item consumption.
RNNs are state-of-the-art neural networks that process variable-length time series data to learn rich item representations. Like any neural network, they can be learned through gradient-based optimization. They have been widely used to model the non-linear temporal dynamics of text, speech, and audio, and hence serve as a good candidate for the Spotify music discovery problem.
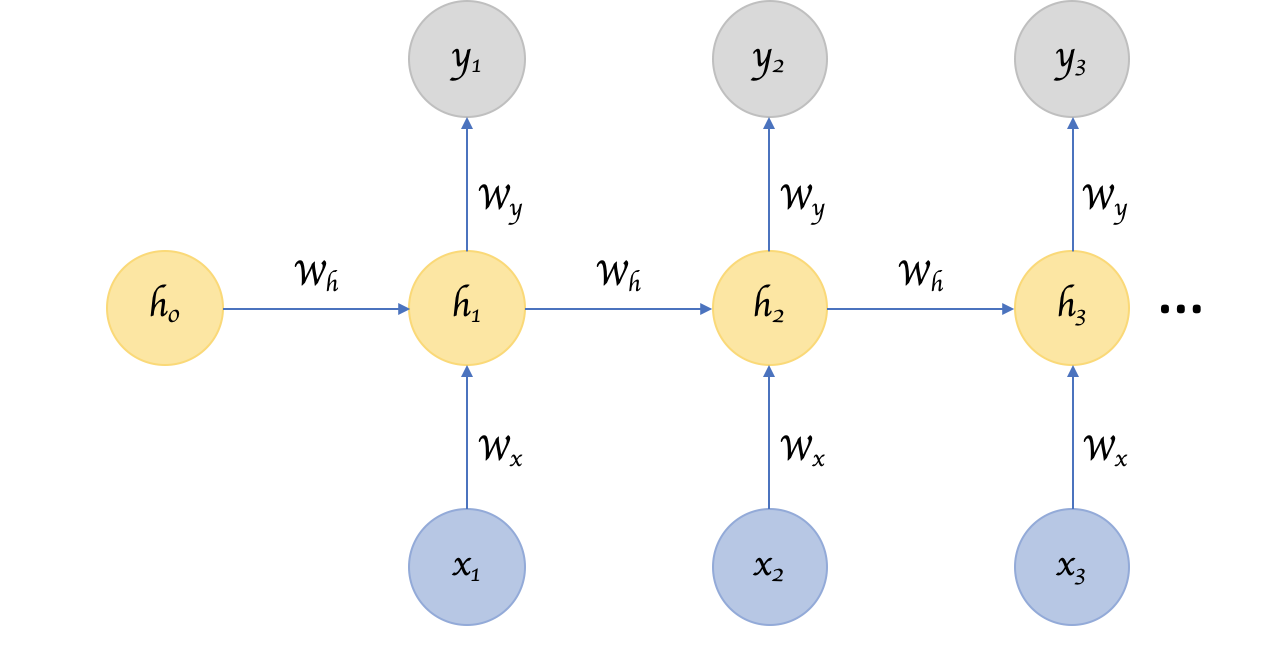
Figure 6 illustrates how an RNN works. Generally, in RNN, at each time step  , an input
, an input  is taken to update the hidden representation
is taken to update the hidden representation  to
to  via a non-linear mapping. Similarly, at each time step, the RNN produces an output
via a non-linear mapping. Similarly, at each time step, the RNN produces an output  as a non-linear function of input and previous hidden state .
as a non-linear function of input and previous hidden state .
We will now see how to train RNNs to predict songs a user might listen to in the future. Figure 7 illustrates the overall pipeline. There are mainly 3 steps:

Step 1: The building blocks of the pipeline are song vector representations, which are already learned from the catalog. To learn these vector representations, Spotify uses Google’s Word2vec suite on the catalog’s top N most popular songs.
More specifically they use the Continuous Bag-of-Words (CBoW) algorithm with negative sampling. As input to the Word2vec algorithm they take user-created playlists of songs. In this, each playlist is considered as an ordered ‘document’ of songs. By scanning all playlists in a windowed fashion, Word2vec will learn a distributed vector representation with fixed dimensionality for every song.
Step 2: The RNN outputs a taste vector, which is a function of song vectors (learned in Step 1) from the user’s listening history and can, therefore, be regarded as a representation of the user’s musical taste. The taste vector should capture how listening behavior changes over time. Thus, the RNN predicts the songs users will likely listen to in the future. To model this, the RNN takes the first  consecutive songs a particular user has listened to and tries predicting the next song vector. In other words,
consecutive songs a particular user has listened to and tries predicting the next song vector. In other words,
,")
where  is the vector of songs listened to by the user at timestamp, and
is the vector of songs listened to by the user at timestamp, and  is the predicted taste vector for future timestamp
is the predicted taste vector for future timestamp  .
.
As a loss function, they minimize the L2 distance between predicted taste vector and future song vector  .
.
Step 3: These taste vectors can now generate song recommendations. Since we have trained the RNN to predict the taste vector lying close (in terms of L2 distance) to future songs a user might play, we can query for nearby songs in that vector space to generate new song recommendations.
To facilitate efficient sampling, Spotify leverages Annoy trees, which are data structures that iteratively divide the vector space into regions using a locality-sensitive hashing random projection technique, enabling approximate nearest neighbor queries.
Playlist Recommendation Using Reinforcement Learning
Overview
One drawback of collaborative filtering approaches is that they rely on explicit or implicit feedback signals that tell whether a user likes a playlist. Hence, they often struggle to consider other important factors (e.g., acoustic coherence, the context of the listening session, and the presence of optimal item sequences). This can lead to a mismatch between offline metrics and user satisfaction metrics (one we want to optimize).
For example, collaborative filtering can suggest a playlist with high ratings but contains a mixture of adult and kid music, which will not lead to good user satisfaction. Hence playlist generation is a difficult task.
Reinforcement learning (RL) is an advanced machine learning area that doesn’t need explicit feedback signals but can instead learn by interacting with users directly. RL agents hence can interact and learn important playlist generation aspects to improve user satisfaction metrics.
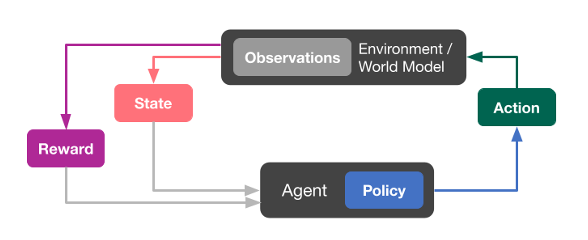
Figure 8 illustrates how RL works. RL problems comprise an environment consisting of a state, action space and rewards, and an RL agent. The RL agent sees the current state of the environment and suggests an action based on the policy learned. The environment then changes its current state to another state based on the action. Besides changing its state, the environment also returns a reward associated with this action. This reward is then consumed by the RL agent to optimize its policy for higher rewards.
Now to apply RL to playlist generation, the problem statement should be formulated as a Markov decision process where:
- States encode the contextual information summarizing user listening sessions
- Action space represents the space of all possible playlists
- Reward is the desired user satisfaction metric
The action space  is the space of all the possible playlists, which is combinatorially complex. For example, generating a playlist of 30 tracks from a pool of 1000 candidates results in an action space with about
is the space of all the possible playlists, which is combinatorially complex. For example, generating a playlist of 30 tracks from a pool of 1000 candidates results in an action space with about  possibilities, making off-the-shelf RL algorithms inapplicable. To resolve this, we instead recommend a single track (from the candidate pool) at a time rather than a complete playlist.
possibilities, making off-the-shelf RL algorithms inapplicable. To resolve this, we instead recommend a single track (from the candidate pool) at a time rather than a complete playlist.
World Model Design
To accurately learn to generate playlists, the RL agent should learn from an environment that mimics actual user listening sessions. To this end, Spotify proposes a world model design that utilizes historical data (e.g., track features and listening history) to model a transition function that produces a new state and its reward based on a specific action.
While mimicking an actual user listening session, the world model should also be able to start a user session, keep track of all listened tracks, and terminate the session. In order to predict the reward associated with an action, the world model applies a user model that is trained to accurately predict the user response to an item (audio track in our case). Such a model is trained on supervised data collected from real users via experimentation.
The training data is generated by randomly shuffling songs from various listening sessions and collecting the percentage of the track completed by the user (if streamed) along with its position within the listening session. This data is then combined with:
- Context Features: User information (e.g., features relating to one’s interests and past interactions)
- Item Features: Information related to the content that the user is interacting with
The user model takes context features of a user and item features  of the track at the
of the track at the  position in the listening session to predict the following three user responses:
position in the listening session to predict the following three user responses:
- Complete the candidate track
- Skip the candidate track
- Listen to the track for more than a specific number of seconds (specified a priori)
Mathematically, the user model takes the following form:
 = f(u, i_t),")
where is a deep neural network that takes the context and item features to predict the user response. Each user response is then mapped to a reward to be used by an RL agent during training.
Action Head DQN Approach
The candidate pool of tracks can keep changing with time because they depend on user listening history and taste. This makes the overall action space dynamic.
To address this, Spotify proposes an Action Head Deep-Q-Network (AH-DQN) agent that takes an action  (e.g., a track to recommend) and current state
(e.g., a track to recommend) and current state  (i.e., user listening session) as input and outputs the recommendation quality
(i.e., user listening session) as input and outputs the recommendation quality ") .
.
The AH-DQN agent (Figure 9) uses a deep neural network to output the recommendation quality . Based on the Q-values of each track, the track with the highest value is selected by the agent. The reward returned by the environment is used to signal how good the action is and update the  -network accordingly. The figure below shows the architecture of the AH-DQN agent.
-network accordingly. The figure below shows the architecture of the AH-DQN agent.
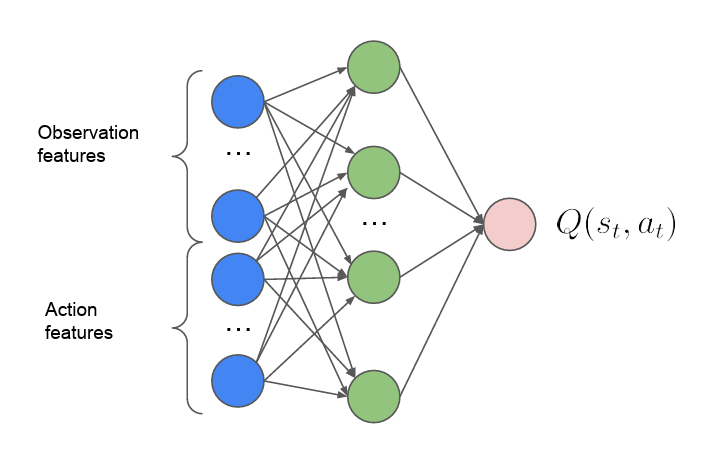
Summary
Spotify is a leading audio streaming platform that offers personalized music and podcast recommendations. In this lesson, we learned how Spotify uses various data sources and machine learning techniques to create different recommendations (e.g., Discover Weekly, playlist recommendation, and music discovery). In this lesson, we discussed:
- Discover Weekly via Matrix Factorization: How Spotify creates a weekly playlist of songs that match the user’s taste using matrix factorization, which decomposes a large matrix of user-song interactions into smaller matrices of user and song features.
- RNNs for Music Discovery: How Spotify uses recurrent neural networks (RNNs) to model the sequential nature of music listening and generate novel songs similar to the user’s previous choices.
- Playlist Recommendation Using Reinforcement Learning: How Spotify uses reinforcement learning (RL) to create playlists that balance exploration and exploitation (i.e., finding new songs that the user might like and playing songs that the user already likes). This tutorial introduces the concept of a world model (a neural network that learns to simulate the user’s behavior and preferences) and an action head (a deep Q-network (DQN) that learns to select the best songs for the playlist).
However, this is just the tip of the iceberg, as there is much more to Spotify recommendation systems. Check out the complete blog series and dive deeper into recommendation systems with lessons that explore various recommendation engines (e.g., Netflix, LinkedIn, Amazon, and YouTube recommendation systems). Gain insights into the techniques used (e.g., text mining, K-nearest neighbor, clustering, matrix factorization, and neural networks).
Citation Information
Mangla, P. “Spotify Music Recommendation Systems,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/v7gpa
@incollection{Mangla_2023_Spotify,
author = {Puneet Mangla},
title = {Spotify Music Recommendation Systems},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/v7gpa},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
[newsletter_optin_form]
The post Spotify Music Recommendation Systems appeared first on PyImageSearch.
October 30, 2023 at 06:30PM
Click here for more details...
=============================
The original post is available in PyImageSearch by Puneet Mangla
this post has been published as it is through automation. Automation script brings all the top bloggers post under a single umbrella.
The purpose of this blog, Follow the top Salesforce bloggers and collect all blogs in a single place through automation.
============================


Post a Comment