Best Machine Learning Datasets : Hector Martinez
by: Hector Martinez
blow post content copied from PyImageSearch
click here to view original post
Table of Contents
- Best Machine Learning Datasets
- Brief Background of Machine Learning
- Importance and Role of Datasets in Machine Learning
- Helping You Find the Best Datasets
- Computer Vision Datasets
- Object Detection
- Image Classification
- Instance Segmentation
- Semantic Segmentation
- Open Source Datasets
- ImageNet
- COCO
- Open Images
- Cityscapes
- IMDB-WIKI
- xView
- Kinetics-700
- UCF101 — Action Recognition
- HMDB51
- NTU RGB+D 120
- Pascal VOC 2012
- CIFAR-10
- CIFAR-100
- MNIST
- Fashion-MNIST
- CelebA
- LSUN
- STL-10
- Street View House Numbers (SVHN)
- Tiny ImageNet
- Oxford-IIIT Pet
- Stanford Cars
- FGVC-Aircraft
- Places365
- ADE20K
- PASCAL Context
- Visual Genome
- VGG-Flowers
- SUN397
- SBU Shadow
- Oxford5k (Oxford Buildings)
- Caltech 256
- MPII Human Pose
- Human3.6M
- Virtual KITTI
- Mapillary Vistas
- Argoverse
- Waymo Open
- nuScenes
- The 10 Largest Publicly Available Datasets
- Government Datasets
- Summary
Best Machine Learning Datasets
This lesson is the 2nd in a 5-part series on Causality in Machine Learning:
- Introduction to Causality in Machine Learning
- Best Machine Learning Datasets (this tutorial)
- Tools and Methodologies for Studying Causal Effect
- A Brief Introduction to Do-Calculus
- Studying Causal Effect with Microsoft’s Do-Why Library

If you are looking to find the best machine learning datasets, you’re in the right place. In this post, we’ll show you the datasets you can use to build your machine learning projects.
If you’re short on time, we’ll cut right to the chase here. We think the best datasets are available for free on Roboflow. After you create a free account, you’ll have access to the best machine learning datasets.
OK, let’s dive into where the various datasets are located to give you a full picture of the dataverse.
Brief Background of Machine Learning
Did you know that machine learning is a part of artificial intelligence that enables computers to learn from data without explicit programming using statistical techniques?
Many call this software 2.0.
In recent years, it has evolved from a mere concept into a technology that significantly impacts our daily routines. From email spam filters to voice assistants, movie suggestions, and fraud detection, machine learning plays a vital role in almost every aspect of our lives.
Importance and Role of Datasets in Machine Learning
Data is king. Algorithms are important and require expert knowledge to develop and refine, but they would be useless without data. Datasets are to machine learning what fuel is to a car: they power the entire process.
These datasets, essentially large collections of related information, act as the training field for machine learning algorithms. They allow the algorithms to learn, understand, and make decisions or predictions based on patterns and relationships the algorithm identifies within the data. As such, the quality, diversity, and volume of data you feed into your machine learning model can significantly impact the model’s ability to make accurate predictions.
Helping You Find the Best Datasets
In this blog post, we aim to empower both seasoned and novice data scientists by providing a comprehensive guide to the top machine learning datasets available in 2023. We will discuss what to look for in a dataset, provide an overview of the most popular datasets this year, share successful case studies, and even offer guidance on preparing your own dataset for machine learning.
Whether you’re working on a complex AI project or just dipping your toes into machine learning, this guide will provide valuable insights and resources to help you on your journey. So, let’s dive in and explore the fascinating world of machine learning datasets!
Computer Vision Datasets
Object Detection
What Is Object Detection
Object detection is a cool technique that allows computers to see and understand what’s in an image or a video. It can find and label different kinds of objects (e.g., people, animals, cars, buildings, and more). Object detection is useful for many applications (e.g., security, surveillance, self-driving cars, face recognition, and image captioning).
Object detection works by using machine learning or deep learning models that learn from many examples of images with objects and their labels. These models can then look at a new image and predict where the objects are and what they are called. Some popular object detection models are YOLO, Faster R-CNN, SSD, and RetinaNet.
Object Detection Datasets
Racetrack
Starting with the Racetrack, a dataset composed of 3680 images that could be instrumental in training models for self-driving cars.

With this dataset, you could train a machine learning model to recognize road conditions, obstacles, and other critical factors in autonomous driving. This could contribute significantly to the development and improvement of self-driving car technologies.
Personal Protective Equipment
Next, we have the Personal Protective Equipment (PPE) dataset, offering 8,760 images that could serve as an excellent basis for training models to recognize safety gear in workplace settings.

This dataset could be used to train a model to ensure safety regulations are being followed in workplaces (e.g., construction sites, factories, or hospitals). For instance, a trained model could automatically identify whether workers are wearing the necessary safety gear.
Furniture-6k
With its 5894 images, the Furniture-6k dataset could be perfect for those interested in interior design or retail applications.

This dataset provides ample opportunity to create applications for interior design or e-commerce. You could train a model for object recognition so that users can identify different types of furniture. It could also be used for recommendation systems for interior design applications.
Vehicle Detection YOLOv5
In the transportation and surveillance sector, the Vehicle Detection YOLOv5 dataset could be very useful with its large repository of 7524 images.

With this dataset, you could train models for various surveillance and security applications. This could range from monitoring parking spaces to improving traffic management systems. It could also be beneficial for safety and security measures (e.g., detecting unauthorized vehicles in certain areas).
Fruits
For those working in the agricultural or food industry, the Fruits dataset provides a hefty amount of 7949 images.

This dataset offers an excellent resource for creating agricultural or food industry applications. You could train a model to identify different types of fruits, analyze fruit quality, or even predict harvest yields.
Egyptian Hieroglyphics
Finally, for researchers or enthusiasts in the field of historical linguistics or Egyptology, the Egyptian Hieroglyphics dataset presents a unique opportunity with its collection of 3890 images.

This unique dataset could be used for various academic and research purposes. You could train a model to recognize and translate ancient Egyptian hieroglyphics, potentially opening up new avenues in studying and understanding ancient Egyptian culture and language.
In addition to these specific use cases, having access to these datasets also provides an opportunity to practice and hone your machine learning skills, experiment with different algorithms, and gain insights into how different types of data can impact model performance.
Aquarium
The Aquarium dataset features 638 images from aquarium images.

If you’re trying to detect fish or working in aquaculture or fisheries, this dataset is for you.
The world relies increasingly on fish protein, so you might want to check out this fish dataset and explore the world of underwater computer vision.
Cable Damage
The Cable Damage dataset is a great example of a relevant infrastructure and energy dataset.

This dataset is a good fit for people looking to detect infrastructure damage or people conducting inspections with aerial platforms.
You can train a model to detect cable damage and make periodic inspections faster and more accurate with the cable damage dataset.
Image Classification
What Is Image Classification?
In the field of computer vision, image classification is a fundamental task that has significant implications for various practical applications. However, what precisely does image classification entail, and how does it function within the machine learning framework?
Image classification involves assigning a label to an image from a predetermined set of categories. For instance, the machine learning model aims to accurately determine whether the image is of a cat, dog, or bird in an image classification task with those categories.
In the context of machine learning, the process of image classification typically involves the following steps:
- Data Collection: The first step is gathering a dataset of images that have already been labeled with the correct category. This labeled dataset serves as the training data for the machine learning model.
- Feature Extraction: Once the data is collected, the next step is identifying the distinguishing features or characteristics within the images. In the early days of machine learning, this was often done manually, with researchers defining features (e.g., edges, corners, or color histograms). Nowadays, with the advent of deep learning and convolutional neural networks, this process can be automated, allowing the model to learn the most relevant features directly from the data.
- Model Training: With the labeled data and identified features, the next step is to train a machine learning model. This involves feeding the images and their corresponding labels into an algorithm (e.g., a convolutional neural network), which then learns to map the features of each image to its correct label. This process typically involves adjusting the model’s parameters to minimize the difference between the model’s predictions and the actual labels.
- Evaluation and Prediction: After the model has been trained, it can be evaluated on a separate set of images that it has not seen before, known as the test set. This indicates how well the model will perform when classifying new, unseen images. If the model’s performance is satisfactory, it can then be used to classify new images according to the categories it has learned.
From autonomous vehicles that need to identify objects on the road to healthcare applications where images of cells must be classified as benign or malignant, image classification models provide a powerful tool. They transform raw image pixels into meaningful categories, allowing us to build systems that can interpret and understand visual data much as a human would. Despite the complexity of the task, the advancements in machine learning and deep learning have made image classification more accurate and efficient than ever before.
Image Classification Datasets
Corn2
Explore the Corn2 dataset to see 665 images of corn.

Perfect for the person interested in applying computer vision to agriculture, this dataset will get you started on using sensors to identify corn.
Yang
Not going to lie. At PyImageSearch, we’re dog people, but if you’re into cats, then this is your dataset.
The Yang dataset gives you access to 2211 images of cat breeds.

Learn to distinguish cat breeds with this fun dataset.
Instance Segmentation
What Is Instance Segmentation
As we continue our journey into understanding the nuances of computer vision tasks in machine learning, let’s delve into a concept known as instance segmentation. Instance segmentation is often called the “Holy Grail” of image processing due to its complexity and high utility.
In a nutshell, instance segmentation involves identifying each object of interest in an image at the pixel level. Not only does it distinguish between different classes of objects (i.e., image classification) and determine the boundaries of each object (i.e., semantic segmentation), but it also differentiates between separate instances of the same class. For example, in an image with multiple cars, instance segmentation will not only identify each pixel belonging to each car, but also separate Car 1 from Car 2, even though they belong to the same class.
Let’s break down the process of instance segmentation in the context of machine learning:
- Data Collection: Like any machine learning task, instance segmentation starts with gathering a dataset. However, instead of simply labeling the category of an entire image, each object in the image must be annotated at the pixel level. This often requires more time and effort than collecting data for other tasks.
- Feature Extraction: The next step involves extracting features from the images, typically using convolutional neural networks (CNNs). Modern instance segmentation approaches, like Mask R-CNN, use a two-stage process. First, they identify regions of the image that may contain an object (region proposal). Then, they classify these regions and generate a pixel-level mask for each one.
- Model Training: After feature extraction, a machine learning model is trained using the labeled images and their pixel-level annotations. The model learns to classify each pixel in the image and differentiate between different instances of the same class.
- Evaluation and Prediction: Once the model is trained, it can be tested on new images to evaluate its performance. If it can accurately segment objects and distinguish between different instances, it can be used for instance segmentation tasks in the real world.
The utility of instance segmentation is profound across many industries. For instance, in the field of autonomous vehicles, it could be used to understand the environment in great detail — distinguishing between different vehicles, pedestrians, and other objects. In healthcare, it could identify and measure individual cells in medical imagery. Despite the complexities, advances in machine learning, particularly deep learning, have made instance segmentation a viable and valuable tool in computer vision.
Instance Segmentation Datasets
MyShroomClassifier
Learn to classify mushrooms with the MyShroomClassifier dataset, with an impressive 6507 images. You’ll see more mushrooms than you can imagine.

If mushrooms are your thing, this is your dataset.
Semantic Segmentation
What Is Semantic Segmentation
Moving further along our journey into the realm of computer vision tasks, we now arrive at a concept known as semantic segmentation. Semantic segmentation, sometimes called pixel-level classification, is a process that goes beyond simply identifying the objects in an image – it classifies every pixel in the image.
So, what makes semantic segmentation unique? In this task, the machine learning model is trained to assign each pixel in an image to a particular class or category. For example, in a street scene, the model should be able to label each pixel that belongs to a car, a pedestrian, the road, buildings, and so on. Unlike instance segmentation, semantic segmentation does not differentiate between instances of the same class. All cars would be labeled ‘car’ without distinguishing between Car 1 and Car 2.
Let’s take a closer look at the steps involved in semantic segmentation:
- Data Collection: The first step in any machine learning task is gathering a suitable dataset. Semantic segmentation involves collecting images and annotating them at the pixel level for each category of interest. This can be a time-consuming process as it requires precise annotation for every pixel in the image.
- Feature Extraction: Next, the features are extracted from the images. This is typically done using a variant of Convolutional Neural Networks (CNNs) tailored for semantic segmentation tasks (e.g., Fully Convolutional Networks (FCN), SegNet, or U-Net). These networks are designed to output an image the same size as the input, where each pixel’s value represents a class.
- Model Training: With the labeled images and extracted features, a machine learning model is then trained. The model learns to classify each pixel in an image, assigning it to a specific category based on its characteristics and context within the image.
- Evaluation and Prediction: Finally, the model is evaluated on a separate test set of images. If the model’s performance is satisfactory, it can be used to perform semantic segmentation on new, unseen images.
Semantic segmentation has a wide range of applications across various domains. In autonomous driving, it can help identify drivable regions, pedestrians, other vehicles, and more. In the medical field, it can be used for tasks like tumor detection or identifying specific anatomical structures in medical images. Despite being computationally intensive, the level of detail and understanding provided by semantic segmentation makes it an invaluable tool in the world of computer vision.
Semantic Segmentation Datasets
Screw Segmentation
Find over 1,600 images in this dataset to help you find screws, perfect for the construction industry.
Open Source Datasets
ImageNet
ImageNet serves as an extensive visual data repository specifically crafted to facilitate research in visual object recognition. Encompassing over 14 million meticulously hand-annotated images, the project elucidates the objects each image portrays and even offers bounding boxes for a substantial portion of over 1 million images. The vast array of over 20,000 categories, each represented by hundreds of images of typical items like “balloon” or “strawberry,” further enhances its utility.

Researchers use ImageNet as a tool to both train and gauge the efficacy of their computer vision algorithms. Simultaneously, businesses harness its potential to engineer products that hinge on image recognition, including image search engines, autonomous vehicles, and facial recognition software.
Here are some of the people who would want to use ImageNet:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of artificial intelligence
ImageNet is a valuable resource for anyone who is working on or interested in computer vision. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. ImageNet is also a valuable resource for businesses that are developing products that rely on image recognition.
COCO
COCO (Common Objects in Context) is a large-scale dataset for object detection, segmentation, and captioning. This powerful dataset has over 330,000 images, each annotated with 80 object categories and 5 captions describing the scenes.

Here are some of the people who would want to use COCO:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of artificial intelligence
COCO is a valuable resource for anyone who is working on or interested in computer vision. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. COCO is also a valuable resource for businesses that are developing products that rely on image recognition.
Open Images
Open Images dataset is a large-scale dataset of images with annotations for object detection, segmentation, and other tasks. It contains over 9 million images, each annotated with bounding boxes, object segmentations, visual relationships, and localized narratives. The dataset is also split into training, validation, and test sets, making it ideal for training and evaluating machine learning models.

The Open Images Dataset is a valuable resource for anyone who is working on or interested in computer vision. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. The dataset is also well-curated and easy to use, making it a valuable tool for researchers and developers alike.
Here are some of the people who would want to use the Open Images Dataset:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of artificial intelligence
Here are some of the tasks that the Open Images Dataset can be used for:
- Object detection
- Semantic segmentation
- Instance segmentation
- Visual relationships
- Localized narratives
- Image captioning
- Visual question answering
The Open Images Dataset is a powerful tool for computer vision research and development. It is a valuable resource for anyone who is working on or interested in this field.
Cityscapes
The Cityscapes dataset is a large-scale dataset of urban street scenes. It contains over 5,000 images, each annotated with pixel-level semantic segmentation labels. The dataset is split into training, validation, and test sets, making it ideal for training and evaluating machine learning models for semantic segmentation of urban street scenes.

The Cityscapes dataset is a valuable resource for anyone who is working on or interested in semantic segmentation of urban street scenes. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. The dataset is also well-curated and easy to use, making it a valuable tool for researchers and developers alike.
Here are some of the people who would want to use the Cityscapes dataset:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of autonomous driving
Here are some of the tasks that the Cityscapes dataset can be used for:
- Semantic segmentation of urban street scenes
- Object detection in urban street scenes
- Scene understanding in urban street scenes
- Autonomous driving
The Cityscapes dataset is a powerful tool for computer vision research and development. It is a valuable resource for anyone who is working on or interested in this field.
IMDB-WIKI
The IMDB-WIKI dataset is a large-scale dataset of face images with gender and age labels. It contains over 500,000 images, each annotated with gender and age labels. The dataset is split into training, validation, and test sets, making it ideal for training and evaluating machine learning models for face recognition and age estimation.

The IMDB-WIKI dataset is a valuable resource for anyone who is working on or interested in face recognition and age estimation. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. The dataset is also well-curated and easy to use, making it a valuable tool for researchers and developers alike.
Here are some of the people who would want to use the IMDB-WIKI dataset:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of artificial intelligence
Here are some of the tasks that the IMDB-WIKI dataset can be used for:
- Face recognition
- Age estimation
- Facial expression recognition
- Facial landmark detection
The IMDB-WIKI dataset is a powerful tool for computer vision research and development. It is a valuable resource for anyone who is working on or interested in this field.
xView
The xView dataset is a large-scale dataset of overhead imagery. It contains images from complex scenes around the world, annotated using bounding boxes. It contains over 1M object instances from 60 different classes.

The xView dataset is a valuable resource for anyone who is working on or interested in object detection in overhead imagery. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. The dataset is also well-curated and easy to use, making it a valuable tool for researchers and developers alike.
Here are some of the people who would want to use the xView dataset:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of autonomous driving
- Anyone who is interested in the future of disaster relief
Here are some of the tasks that the xView dataset can be used for:
- Object detection in overhead imagery
- Scene understanding in overhead imagery
- Autonomous driving
- Disaster relief
The xView dataset is a powerful tool for computer vision research and development. It is a valuable resource for anyone who is working on or interested in this field.
Kinetics-700
Kinetics-700 is a large-scale, high-quality dataset for human action recognition in videos. It consists of around 650,000 video clips covering 700 human action classes with at least 700 video clips for each action class. The videos are collected from YouTube and are of high quality, with good resolution and frame rate. The action classes are diverse and cover a wide range of human activities (e.g., playing sports, dancing, and interacting with objects).

Kinetics-700 is a valuable resource for anyone who is working on or interested in human action recognition. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. The dataset is also well-curated and easy to use, making it a valuable tool for researchers and developers alike.
Here are some of the people who would want to use Kinetics-700:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of artificial intelligence
Here are some of the tasks that Kinetics-700 can be used for:
- Human action recognition
- Video summarization
- Video question answering
- Video captioning
UCF101 — Action Recognition
UCF101 — Action Recognition is a large-scale dataset of realistic action videos, collected from YouTube, having 101 action categories. Each action category has at least 30 video clips, with a total of 13320 videos. The videos are of high quality, with good resolution and frame rate. The action categories are diverse and cover a wide range of human activities (e.g., playing sports, dancing, and interacting with objects).

UCF101 is a valuable resource for anyone who is working on or interested in action recognition. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. The dataset is also well-curated and easy to use, making it a valuable tool for researchers and developers alike.
Here are some of the people who would want to use UCF101:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of artificial intelligence
HMDB51
HMDB51 is a large-scale dataset of realistic action videos, collected from movies and YouTube, having 51 action categories. Each action category has at least 101 video clips, with a total of 6,766 videos. The videos are of high quality, with good resolution and frame rate. The action categories are diverse and cover a wide range of human activities (e.g., playing sports, dancing, and interacting with objects).
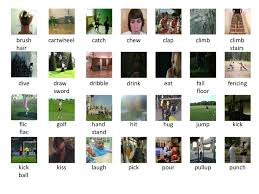
HMDB51 is a valuable resource for anyone who is working on or interested in action recognition. It is a large and comprehensive dataset that can be used to train and evaluate algorithms. The dataset is also well-curated and easy to use, making it a valuable tool for researchers and developers alike.
Here are some of the people who would want to use HMDB51:
- Computer vision researchers
- Data scientists
- Software engineers
- Business developers
- Anyone who is interested in the future of artificial intelligence
Here are some of the tasks that HMDB51 can be used for:
- Action recognition
- Video summarization
- Video question answering
- Video captioning
NTU RGB+D 120
NTU RGB+D 120 is an expansive dataset for RGB+D human action recognition, comprising 114 thousand video samples and 8 million frames gathered from 106 unique subjects. This comprehensive dataset accommodates 120 varied action classes, incorporating everyday activities, interactive actions, and health-related movements.

This voluminous dataset is partitioned into training, validation, and test sets, occupying 80%, 10%, and 10% of the total samples. The training set acts as a crucible for model training, the validation set assists in gauging the model’s performance, and the test set allows for performance appraisal on unfamiliar data.
Three synchronized and calibrated Kinect V2 cameras captured the dataset, ensuring consistent data quality. Additionally, the data comes annotated with 3D joint coordinates of the subjects, facilitating the training of models to monitor the subjects’ movements in three dimensions.
NTU RGB+D 120 proves to be an invaluable asset for those immersed in or intrigued by RGB-D human action recognition. Its sheer size and diversity make it ideal for training and evaluating pertinent algorithms. Its meticulous curation and user-friendly design make it a robust tool for researchers and developers alike.
Pascal VOC 2012
Pascal VOC 2012 is a large-scale dataset of images used for object detection and image classification. It was first released in 2005 and has been updated several times since then. The latest version, Pascal VOC 2012, contains 11,500 images divided into 20 object classes. The images are high-quality and come from a variety of sources, including the web, the PASCAL Visual Object Classes Challenge, and the LabelMe dataset.
Pascal VOC is a popular dataset for benchmarking object detection and image classification algorithms. It has been used in a variety of research papers, and its results are often used to compare different algorithms. The dataset is also used by many companies to train their object detection and image classification models.
If you are interested in object detection or image classification, Pascal VOC is a great resource. It is a large and comprehensive dataset that can be used to train and evaluate your algorithms. The images are high-quality and come from a variety of sources, which makes it a realistic testbed for your algorithms.
CIFAR-10
The CIFAR-10 (Canadian Institute for Advanced Research, 10 classes) dataset is a collection of 60,000 32×32 color images in 10 classes, with 6,000 images per class. The 10 classes are:
- Airplane
- Automobile
- Bird
- Cat
- Deer
- Dog
- Frog
- Horse
- Ship
- Truck

The CIFAR-10 dataset is a popular benchmark for machine learning algorithms, particularly for image classification. The dataset is relatively small and easy to work with, which makes it a good choice for beginners. However, the dataset is also challenging, and it can be difficult to achieve high accuracy on the test set.
The CIFAR-10 dataset was created by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The dataset was first published in 2009, and it has been used in a variety of machine learning research papers.
The dataset can be downloaded in a variety of formats, including JPEG, PNG, and raw pixel data.
The CIFAR-10 dataset is a valuable resource for machine learning researchers and practitioners. The dataset is small and easy to work with, and it is also challenging, which makes it a good choice for evaluating the performance of machine learning algorithms.
CIFAR-100
The CIFAR-100 (Canadian Institute for Advanced Research, 100 classes) dataset is a collection of 60,000 32×32 color images in 100 classes, with 600 images per class. The 100 classes are grouped into 20 superclasses. The 20 superclasses are:
- Aquatic Animals
- Animals
- Artifacts
- Buildings
- Fruits and Vegetables
- Insects
- Large Animals
- Man-made Outdoor Scenes
- Natural Outdoor Scenes
- People
- Small Animals
- Sports
- Transportation

The CIFAR-100 dataset is a popular benchmark for machine learning algorithms, particularly for image classification. The dataset is relatively small and easy to work with, which makes it a good choice for beginners. However, the dataset is also challenging, and it can be difficult to achieve high accuracy on the test set.
The CIFAR-100 dataset was created by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The dataset was first published in 2009, and it has been used in a variety of machine learning research papers.
The dataset can be downloaded in a variety of formats, including JPEG, PNG, and raw pixel data.
MNIST
Think of the MNIST (Modified National Institute of Standards and Technology) as this huge treasure chest filled with tens of thousands of handwritten digits. It’s like a playground that image processing systems use to improve their work. And guess what? It’s not just them. Machine learning buffs love it, too, for training and testing their models!

Here’s a fun fact: MNIST didn’t just come out of nowhere. The folks who made it took the original samples from NIST’s datasets and gave them a remix. They had a hunch that their data, with samples from American Census Bureau workers and American high school students, wouldn’t be a great fit for machine learning experiments.
So, what does the MNIST database look like? It’s pretty hefty, holding 60,000 training images and 10,000 more for testing. They didn’t play favorites either — half the training and testing images came from NIST’s original training set and the other half from NIST’s testing set.
The creators kept track of the different techniques they tried on this dataset. In their debut paper, they used a support-vector machine and only messed up 0.8% of the time. Not too shabby, right?
But things didn’t stop at MNIST. The people at NIST developed an improved dataset called Extended MNIST (EMNIST). This is seen as the heir to the MNIST throne, boasting more than just images of handwritten digits.
The MNIST database is a valuable resource for machine learning researchers and practitioners. The dataset is large, diverse, and well-organized, which makes it a good choice for training and evaluating image processing systems. However, the dataset is not balanced and not updated regularly, which are some of its limitations.
Fashion-MNIST
Fashion-MNIST is a dataset of Zalando’s article images consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28×28 grayscale image, associated with a label from 10 classes.

The classes are:
- T-shirt/top
- Trouser
- Pullover
- Dress
- Coat
- Sandal
- Shirt
- Sneaker
- Bag
- Ankle boot
Fashion-MNIST was created as a drop-in replacement for the MNIST dataset, which contains handwritten digits. The goal was to create a dataset that is similar in size and format to MNIST, but that is more challenging and interesting for machine learning researchers.
Fashion-MNIST has been used in a variety of machine learning tasks, including image classification, object detection, and instance segmentation. The dataset has also been used to train deep learning models for fashion-related tasks (e.g., product recommendation and style transfer).
CelebA
CelebA (CelebFaces Attributes): Picture this — a massive collection of more than 200,000 celebrity photos, each one annotated with 40 different attributes. That’s CelebA for you! It’s like the ultimate paparazzi album — instead of red carpet events and award shows, we’ve got a bunch of different poses and backgrounds to work with.

The real beauty of CelebA lies in its diversity. We’re not just talking about a huge number of pictures here, but also a wide variety of faces — 10,177 unique identities, to be exact. Then there’s the sheer volume of data: over 200,000 face images. Plus, every picture is packed with information, with 5 landmarks and 40 binary attributes jotted down for each.
Now, all this isn’t just for show. This dataset is perfect for training and testing computer vision tasks. Want to work on face attribute recognition, face detection, or face recognition? CelebA’s got you covered. Need to pinpoint facial landmarks or delve into face editing and synthesis? Look no further. CelebA is the ultimate playground for anyone working in computer vision.
LSUN
The LSUN dataset is a large-scale image dataset that was created by Yu et al. in 2015. The dataset contains around 10 million images, each of which is 256×256 pixels in size. The images in the LSUN dataset are divided into 10 scene categories and 20 object categories.

The scene categories are:
- bedroom
- bathroom
- kitchen
- living room
- dining room
- office
- church
- outdoor
- street
- house
The object categories are:
- airplane
- car
- cat
- dog
- horse
- motorbike
- person
- plant
- sheep
- tv
The LSUN dataset was created using a combination of human labeling and deep learning. First, a large set of candidate images was collected. Then, a subset of these images was labeled by humans. The remaining images were then classified by a deep learning model. The images that were classified with high confidence were then labeled by humans. This process was repeated until all of the images had been labeled.
STL-10
The STL-10 dataset is a popular image recognition dataset that was created by Ameet Talwalkar et al. in 2010. The dataset contains 10 classes of objects, each with 500 training images and 1000 test images. The objects are:
- airplane
- bird
- car
- cat
- deer
- dog
- horse
- monkey
- ship
- truck

The images in the STL-10 dataset are 96×96 pixels in size and are stored in the JPEG format.
Street View House Numbers (SVHN)
The Street View House Numbers (SVHN) dataset is a large-scale dataset of house numbers taken from Google Street View images. It is a popular dataset for training and evaluating machine learning models for digit recognition. The dataset contains over 600,000 images, each of which is 32×32 pixels in size. The images are divided into a training set of 73,257 images, a test set of 26,032 images, and an extra set of 531,131 images. The images in the training and test sets are all centered on a single digit, while the images in the extra set may contain multiple digits.

The SVHN dataset is a challenging dataset for digit recognition due to the following factors:
- The images are taken from real-world environments, which means that they can be noisy and contain a variety of different objects.
- The digits in the images are not always perfectly centered or aligned.
- The digits in the images can be of different sizes and fonts.
Despite these challenges, the SVHN dataset has been used to train and evaluate a variety of machine learning models for digit recognition. These models have achieved high accuracy on the SVHN dataset, and they have also been shown to be effective on other datasets of real-world images.
Tiny ImageNet
Tiny ImageNet is a subset of the ImageNet dataset, which is a large-scale dataset of labeled images. Tiny ImageNet contains 100,000 images of 200 classes (500 for each class) downsized to 64×64 colored images. Each class has 500 training images, 50 validation images, and 50 test images.

Tiny ImageNet is a popular dataset for training and evaluating image classification models. It is a challenging dataset because the images are small and low-resolution, and the classes are visually similar. However, Tiny ImageNet is also a relatively small dataset, which makes it easy to train and evaluate models on a personal computer.
If you are interested in training an image classification model, then Tiny ImageNet is a great resource to consider. The dataset is small and easy to download, which makes it ideal for experiments and prototyping. The images in the dataset are also high-quality and well-labeled, which makes it easy to train accurate models.
Oxford-IIIT Pet
The Oxford-IIIT Pet dataset is a large-scale dataset of images of pets. The dataset contains 37 categories of pets, each with roughly 200 images. The images in the dataset are all 256×256 pixels in size. The dataset was created by the Visual Geometry Group at Oxford and the Indian Institute of Technology, Bombay.

The Oxford-IIIT Pet dataset has been used in a variety of research papers to train deep learning models for pet classification. The dataset is a valuable resource for researchers who are working on deep learning models for image processing tasks.
Here are some of the benefits of using the Oxford-IIIT Pet dataset:
- The dataset is large and diverse, which makes it ideal for training deep learning models.
- This dataset is well curated with accurate, relevant images.
- The dataset is open source, which means that it is free to use and share.
Stanford Cars
The Stanford Cars dataset is a large-scale dataset of images of cars. The dataset contains 16,185 images of 196 classes of cars. The images in the dataset are all 360×240 pixels in size. The dataset was created by Fei-Fei Li and her students at Stanford University.

The Stanford Cars dataset has been used in a variety of research papers to train deep learning models for car classification. The dataset is a valuable resource for researchers who are working on deep learning models for image processing tasks.
FGVC-Aircraft
The FGVC-Aircraft (Fine-Grained Visual Classification of Aircraft) dataset is a large-scale dataset of images of aircraft. It was created by the Visual Geometry Group (VGG) at the University of Oxford. The dataset contains 10,200 images of 102 different aircraft model variants. Each image is labeled with the aircraft model variant and a tight bounding box.

The FGVC-Aircraft dataset is a valuable resource for researchers who are working on fine-grained image classification and recognition tasks. The dataset is large and diverse, which makes it ideal for training deep learning models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train accurate models.
The FGVC-Aircraft dataset has been used in a variety of research papers to train deep learning models for fine-grained image classification and recognition. These models have achieved state-of-the-art results on the FGVC-Aircraft dataset, and they have also been shown to be effective on other datasets of fine-grained images.
If you are interested in training a deep learning model for fine-grained image classification and recognition, then the FGVC-Aircraft dataset is a great resource to consider. The dataset is large and diverse, which means that it can be used to train accurate models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
Places365
The Places365 dataset is a large-scale dataset of images of scenes. It was created by the Visual Geometry Group (VGG) at the University of Oxford. The dataset contains 10 million images of 434 scene classes. The images in the dataset are all 256×256 pixels in size.

The Places365 dataset is a valuable resource for researchers who are working on scene recognition tasks. The dataset is large and diverse, which makes it ideal for training deep learning models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train accurate models.
The Places365 dataset has been used in a variety of research papers to train deep learning models for scene recognition. These models have achieved state-of-the-art results on the Places365 dataset, and they have also been shown to be effective on other datasets of scene images.
If you are interested in training a deep learning model for scene recognition, then the Places365 dataset is a great resource to consider. The dataset is large and diverse, which means that it can be used to train accurate models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
ADE20K
The ADE20K dataset is a large-scale dataset of images with pixel-level semantic annotations. It was created by researchers at MIT and contains 20,000 images annotated with 150 object categories and 50 stuff categories. The images in the dataset are of high quality and come from a variety of sources, including the web and Google Street View.

The ADE20K dataset is a valuable resource for researchers who are working on semantic segmentation tasks. Semantic segmentation is the task of assigning a semantic label to each pixel in an image. This can be used for a variety of tasks (e.g., scene understanding, object detection, and autonomous driving).
The ADE20K dataset has been used in a variety of research papers to train deep learning models for semantic segmentation. These models have achieved state-of-the-art results on the ADE20K dataset, and they have also been shown to be effective on other datasets of semantic segmentation images.
PASCAL Context
The PASCAL Context dataset is a large-scale dataset of images with pixel-level semantic annotations. It was created by researchers at the University of Maryland and contains 10,103 images annotated with 59 object categories and 20 stuff categories. The images in the dataset are of high quality and come from various sources, including the web and Google Street View.

The PASCAL Context dataset is a valuable resource for researchers working on semantic segmentation tasks. Semantic segmentation is the task of assigning a semantic label to each pixel in an image. This can be used for a variety of tasks (e.g., scene understanding, object detection, and autonomous driving).
The PASCAL Context dataset has been used in various research papers to train deep learning models for semantic segmentation. These models have achieved state-of-the-art results on the PASCAL Context dataset, and they have also been shown to be effective on other datasets of semantic segmentation images.
Visual Genome
The Visual Genome dataset is a large-scale dataset of images with rich annotations. It was created by researchers at Stanford University and contains 101,174 images with 1.7 million scene graphs. Each scene graph is a representation of the objects, attributes, and relationships in an image.

The Visual Genome dataset is a valuable resource for researchers who are working on a variety of tasks, including:
- Object detection
- Scene understanding
- Visual question answering
- Image captioning
- Natural language generation
VGG-Flowers
The VGG-Flowers dataset is a dataset of 102 flower categories, with 1020 images per class. The images are of high quality and are taken from a variety of sources, including the web and Flickr. The dataset is split into training, validation, and test sets, with 6600, 1800, and 1800 images, respectively.

The VGG-Flowers dataset is a valuable resource for researchers who are working on flower classification tasks. The dataset is large and diverse, which makes it ideal for training deep learning models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
The VGG-Flowers dataset has been used in a variety of research papers to train deep learning models for flower classification. These models have achieved state-of-the-art results on the VGG-Flowers dataset, and they have also been shown to be effective on other datasets of flower images.
If you are interested in training a deep learning model for flower classification, then the VGG-Flowers dataset is a great resource to consider. The dataset is large and diverse, which means that it can be used to train accurate models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
SUN397
The Scene UNderstanding (SUN) database contains 899 categories and 130,519 images. There are 397 well-sampled categories to evaluate numerous state-of-the-art algorithms for scene recognition.

The SUN397 dataset is a valuable resource for researchers who are working on scene recognition tasks. The dataset is large and diverse, which makes it ideal for training deep learning models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
The SUN397 dataset has been used in a variety of research papers to train deep learning models for scene recognition. These models have achieved state-of-the-art results on the SUN397 dataset, and they have also been shown to be effective on other datasets of scene images.
SBU Shadow
The SBU (Stony Brook University) Shadow dataset is a large-scale dataset of images with shadows and noisy labels. It was created by researchers at SBU and contains 100,000 images annotated with 20 object categories. The images in the dataset are of high quality and come from a variety of sources, including the web and Google Street View.

The SBU Shadow dataset is a valuable resource for researchers who are working on object detection tasks in the presence of shadows and noisy labels. The dataset is large and diverse, which makes it ideal for training deep learning models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
The SBU Shadow dataset has been used in a variety of research papers to train deep learning models for object detection in the presence of shadows and noisy labels. These models have achieved state-of-the-art results on the SBU Shadow dataset, and they have also been shown to be effective on other datasets of images with shadows and noisy labels.
Oxford5k (Oxford Buildings)
The Oxford5k (Oxford Buildings) dataset is a dataset of 5062 images of 11 different landmark buildings in Oxford, UK. The images were collected from Flickr and are of varying quality. The dataset is split into a training set of 4562 images and a test set of 500 images.

The Oxford5k dataset is a valuable resource for researchers who are working on building recognition tasks. The dataset is relatively small, but it is well-curated and includes a variety of different viewpoints of each building. This makes it a good choice for training and evaluating models that are designed to work with real-world images.
The Oxford5k dataset has been used in a variety of research papers to train and evaluate building recognition models. These models have achieved state-of-the-art results on the Oxford5k dataset, and they have also been shown to be effective on other datasets of building images.
Caltech 256
The Caltech 256 dataset is a dataset of 30,607 real-world images, of different sizes, spanning 257 object categories (256 object classes and an additional clutter class). Each class is represented by at least 80 images. The dataset is a superset of the Caltech-101 dataset.

The dataset was created by researchers at Caltech and contains images of a variety of objects, including animals, vehicles, and everyday objects. The images are of high quality and are taken from a variety of sources, including the web and Flickr.
MPII Human Pose
The MPII Human Pose dataset is a large-scale dataset of human poses in images. It consists of 25,000 images of people performing a variety of activities (e.g., walking, running, and playing sports). Each image is annotated with the 2D coordinates of 16 keypoints on the human body.

The MPII (Max Planck Institute for Informatics) Human Pose dataset is a valuable resource for researchers who are working on human pose estimation tasks. The dataset is large and diverse, which makes it ideal for training deep learning models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
The MPII Human Pose dataset has been used in a variety of research papers to train deep learning models for human pose estimation. These models have achieved state-of-the-art results on the MPII Human Pose dataset, and they have also been shown to be effective on other datasets of human pose images.
Human3.6M
Human3.6M is a large-scale dataset of human poses in images and videos. It consists of 3.6 million images and videos of 11 professional actors performing a variety of activities (e.g., walking, running, and playing sports). Each image and video is annotated with the 3D coordinates of 25 keypoints on the human body.

The Human3.6M dataset is a valuable resource for researchers who are working on human pose estimation tasks. The dataset is large and diverse, which makes it ideal for training deep learning models. The images and videos in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
The Human3.6M dataset has been used in a variety of research papers to train deep learning models for human pose estimation. These models have achieved state-of-the-art results on the Human3.6M dataset, and they have also been shown to be effective on other datasets of human pose images and videos.
Virtual KITTI
The Virtual KITTI dataset is a synthetic dataset for training and evaluating computer vision models for several video understanding tasks: object detection and multi-object tracking, scene-level and instance-level semantic segmentation, optical flow, and depth estimation. The dataset is created using the Unity game engine and contains 50 high-resolution monocular videos (21,260 frames) generated from five different virtual worlds in urban settings under different imaging and weather conditions. These worlds were created using a novel real-to-virtual cloning method.

The Virtual KITTI dataset is a valuable resource for researchers who are working on computer vision tasks that require large amounts of data. The dataset is large and diverse, which makes it ideal for training deep learning models. The images in the dataset are also high-quality and well-labeled, which makes it easy to train and evaluate models.
The Virtual KITTI dataset has been used in a variety of research papers to train deep learning models for computer vision tasks. These models have achieved state-of-the-art results on the Virtual KITTI dataset, and they have also been shown to be effective on other datasets of real-world images.
Mapillary Vistas
Mapillary Vistas dataset is a diverse street-level imagery dataset with pixel‑accurate and instance‑specific human annotations for understanding street scenes around the world.

Argoverse
Argoverse is a pretty cool tracking benchmark with a ton of data — more than 30,000 scenarios — collected from the streets of Pittsburgh and Miami. Here’s the interesting part: each of these scenarios is a series of frames, like a mini-movie, sampled at a speed of 10 frames per second.

In each sequence, there’s this cool character we like to call the “agent.” And the main mission, should you accept it, is to predict where this “agent” will be in the next 3 seconds. A bit of fortune-telling!
But there’s more! These sequences aren’t just one big jumbled mess. They’re neatly divided into training, validation, and test sets, with around 205,942, 39,472, and 78,143 sequences each. And here’s the kicker: these splits have no geographical overlap. So, each set is like a unique little world of its own.
So yeah, that’s Argoverse for you. Pretty neat, huh?
Waymo Open
Waymo Open dataset is a collection of data and tools that can be used to develop and evaluate autonomous driving systems. The dataset includes high-resolution sensor data (e.g., LiDAR and cameras), as well as labels for objects in the environment. The data is collected from Waymo’s fleet of self-driving cars, which have driven over 10 million miles in a variety of environments.

The Waymo Open dataset is designed to help researchers and developers build better autonomous driving systems. The data can be used to train models to detect and track objects, predict their behavior, and plan safe paths. The dataset can also be used to evaluate the performance of autonomous driving systems.
The Waymo Open dataset is available for free to researchers and developers. To access the dataset, you must create an account on the Waymo website. Once you have an account, you can download the data and tools.
nuScenes
The nuScenes dataset is a large-scale autonomous driving dataset that was released in 2019. The dataset contains 1000 scenes collected in Boston and Singapore, with each scene containing 20 seconds of 360-degree LiDAR, camera, and radar data. The data is annotated with 3D bounding boxes, instance segmentations, and semantic segmentations for 23 object classes and 8 attributes.

The nuScenes dataset is a valuable resource for researchers and developers who are working on autonomous driving systems. The dataset provides a large and diverse set of data that can be used to train and evaluate autonomous driving systems.
The 10 Largest Publicly Available Datasets
- Google Earth Engine: This dataset contains over 1.5TB of satellite imagery and other geospatial data. It is used for a variety of purposes, including climate change research, disaster response, and urban planning.
- CERN Open Data Portal: This dataset contains over 2PB of data from the Large Hadron Collider particle accelerator. It is used by physicists to study the fundamental particles of nature.
- National Oceanic and Atmospheric Administration (NOAA): This dataset contains over 20PB of weather and climate data. It is used by scientists to study climate change and other environmental issues.
- European Space Agency (ESA): This dataset contains over 10PB of satellite imagery and other space data. It is used by scientists to study the Earth, the solar system, and the universe.
- Google Scholar: This dataset contains over 100 million academic papers. It is used by researchers to find information on a variety of topics.
- PubMed Central: This dataset contains over 30 million medical research papers. It is used by doctors and other healthcare professionals to stay up-to-date on the latest medical research.
- OpenEI: This dataset contains over 1TB of energy data. It is used by energy companies, governments, and researchers to track energy use and develop energy policies.
- OpenStreetMap: This dataset contains over 200TB of geographic data. It is used by mapmakers, navigation apps, and other location-based services.
- GitHub: This dataset contains over 100 million code repositories. It is used by developers to find and share code.
- Stack Overflow: This dataset contains over 100 million questions and answers about programming. It is used by developers to learn new programming languages and solve problems.
Government Datasets
Governments have massive data. Here are some of the best government datasets.
- Data.gov: This is the United States government’s open data website. It provides access to datasets published by agencies across the federal government. It covers various topics such as agriculture, education, health, finance, and more. The website also offers tools and resources to help users explore and use the data.
- US Census Bureau Data: This is the federal agency that conducts the census and other surveys to collect demographic, social, economic, and geographic data. The agency publishes various datasets and reports based on the data it collects. The data can be used for research, planning, policy making, and business purposes.
- NASA Earth Data: This is a collection of datasets from NASA’s Earth science missions and programs. The data covers various aspects of the Earth system (e.g., climate, land, ocean, atmosphere, and cryosphere). The data can be accessed through web services, tools, and applications.
- CDC COVID Data Tracker: This is a dashboard that provides updated information on the COVID-19 pandemic in the United States. The data includes cases, deaths, testing, vaccination, hospitalization, and variants. The data can be viewed at national, state, county, and metropolitan levels.
- FBI Crime Data Explorer: This is a tool that allows users to access and analyze crime data from the FBI’s Uniform Crime Reporting (UCR) Program. The data includes offenses, arrests, victims, offenders, hate crimes, and law enforcement officers killed or assaulted. The data can be filtered by year, state, agency, offense type, and demographic group.
What's next? I recommend PyImageSearch University.
78 total classes • 97+ hours of on-demand code walkthrough videos • Last updated: July 2023
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 78 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 78 Certificates of Completion
- ✓ 97+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 512+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Great data is necessary for a great machine learning outcome. Therefore, your data’s variety, accuracy, and diversity may be the most important when training machine learning models.
Get the right dataset. Ensure it is properly labeled. This will give you a huge advantage over those working with inferior data.
So, explore your data, choose large and diverse datasets, and remain data-curious through your machine learning journey. The rewards will be well worth the effort.

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.
The post Best Machine Learning Datasets appeared first on PyImageSearch.
July 31, 2023 at 06:30PM
Click here for more details...
=============================
The original post is available in PyImageSearch by Hector Martinez
this post has been published as it is through automation. Automation script brings all the top bloggers post under a single umbrella.
The purpose of this blog, Follow the top Salesforce bloggers and collect all blogs in a single place through automation.
============================


Post a Comment